
In this article, you’ll learn what image recognition is and how it’s related to computer vision. You’ll also find out what neural networks are and how they learn to recognize what is depicted in images. Finally, we’ll discuss some of the use cases for this technology across industries.
What is image recognition and computer vision?
Image recognition (or image classification) is the task of identifying images and categorizing them in one of several predefined distinct classes. So, image recognition software and apps can define what’s depicted in a picture and distinguish one object from another.The field of study aimed at enabling machines with this ability is called computer vision. Being one of the computer vision (CV) tasks, image classification serves as the foundation for solving different CV problems, including:
Image classification with localization – placing an image in a given class and drawing a bounding box around an object to show where it’s located in an image.

Image classification vs image classification with localization. Source: KDnuggets
Object detection – categorizing multiple different objects in the image and showing the location of each of them with bounding boxes. So, it’s a variation of the image classification with localization tasks for numerous objects.Object (semantic) segmentation – identifying specific pixels belonging to each object in an image instead of drawing bounding boxes around each object as in object detection.
Instance segmentation – differentiating multiple objects (instances) belonging to the same class (each person in a group).

The difference between object detection, semantic segmentation, and instance segmentation. Source: Conditional Random Fields Meet Deep Neural Networks for Semantic Segmentation
Researchers can use deep learning models for solving computer vision tasks. Deep learning is a machine learning technique that focuses on teaching machines to learn by example. Since most deep learning methods use neural network architectures, deep learning models are frequently called deep neural networks.Deep neural networks: the “how” behind image recognition and other computer vision techniques
Image recognition is one of the tasks in which deep neural networks (DNNs) excel. Neural networks are computing systems designed to recognize patterns. Their architecture is inspired by the human brain structure, hence the name. They consist of three types of layers: input, hidden layers, and output. The input layer receives a signal, the hidden layer processes it, and the output layer makes a decision or a forecast about the input data. Each network layer consists of interconnected nodes (artificial neurons) that do the computation.

For visual types -- go watch our video explaining the technicalities of image recognition
What makes a neural network deep? The number of hidden layers: While traditional neural networks have up to three hidden layers, deep networks may contain hundreds of them.
How neural networks learn to recognize patterns
How do we understand whether a person passing by on the street is an acquaintance or a stranger (complications like short-sightedness aren’t included)? We look at them, subconsciously analyze their appearance, and if some inherent features – face shape, eye color, hairstyle, body type, gait, or even fashion choices – match with a specific person we know, we recognize this individual. This brainwork takes just a moment.So, to be able to recognize faces, a system must learn their features first. It must be trained to predict whether an object is X or Z. Deep learning models learn these characteristics in a different way from machine learning (ML) models. That's why model training approaches are different as well.
Training deep learning models (such as neural networks)
To build an ML model that can, for instance, predict customer churn, data scientists must specify what input features (problem properties) the model will consider in predicting a result. That may be a customer’s education, income, lifecycle stage, product features, or modules used, number of interactions with customer support and their outcomes. The process of constructing features using domain knowledge is called feature engineering.If we were to train a deep learning model to see the difference between a dog and a cat using feature engineering… Well, imagine gathering characteristics of billions of cats and dogs that live on this planet. We can’t construct accurate features that will work for each possible image while considering such complications as viewpoint-dependent object variability, background clutter, lighting conditions, or image deformation. There should be another approach, and it exists thanks to the nature of neural networks.
Neural networks learn features directly from data with which they are trained, so specialists don’t need to extract features manually.
“The power of neural networks comes from their ability to learn the representation in your training data and how to best relate it to the output variable that you want to predict. In this sense, neural networks learn mapping. Mathematically, they are capable of learning any mapping function and have been proven to be universal approximation algorithms,” notes Jason Brownlee in Crash Course On Multi-Layer Perceptron Neural Networks.
The training data, in this case, is a large dataset that contains many examples of each image class. When we say a large dataset, we really mean it. For instance, the ImageNet dataset contains more than 14 million human-annotated images representing 21,841 concepts (synonym sets or synsets according to the WordNet hierarchy), with 1,000 images per concept on average.
Each image is annotated (labeled) with a category it belongs to – a cat or dog. The algorithm explores these examples, learns about the visual characteristics of each category, and eventually learns how to recognize each image class. This model training style is called supervised learning.
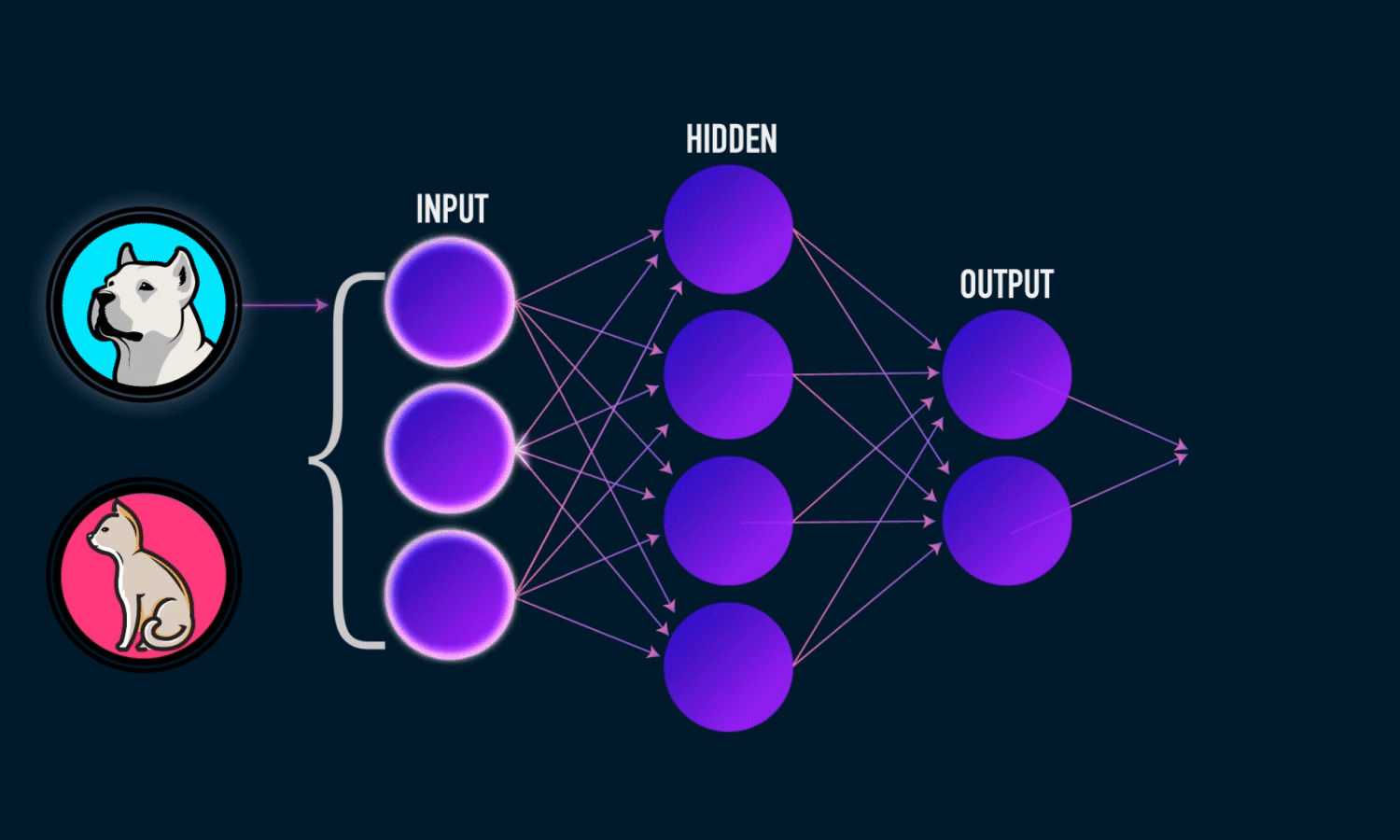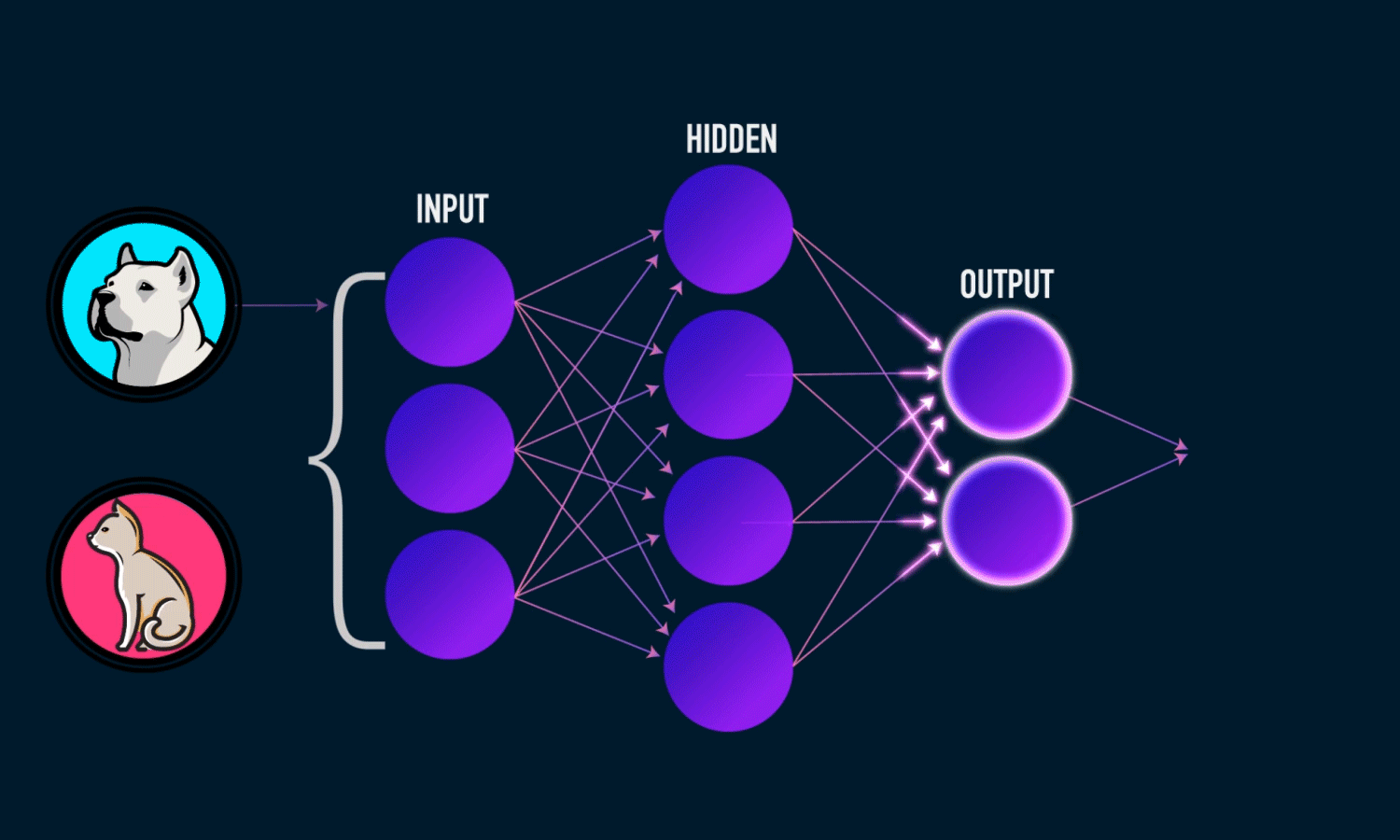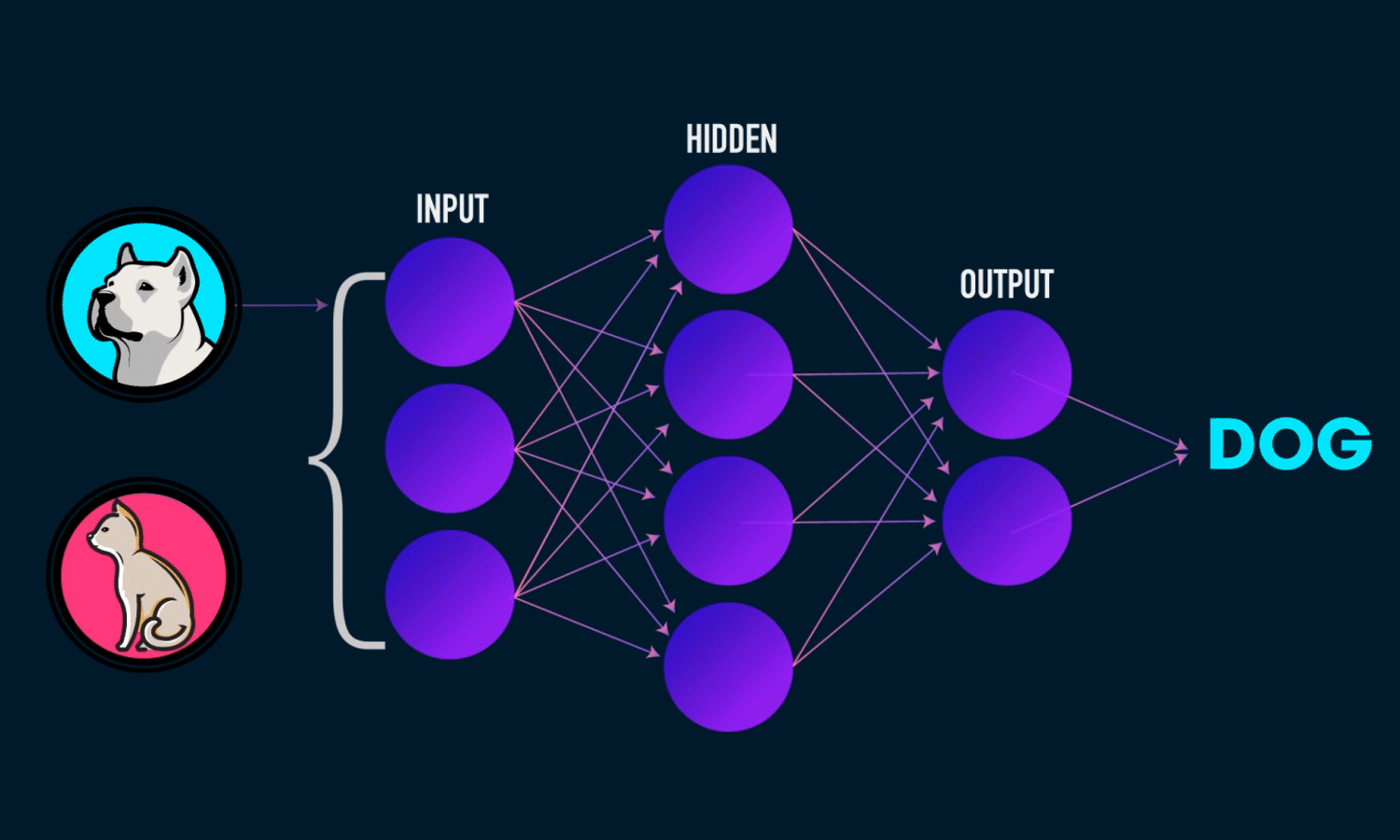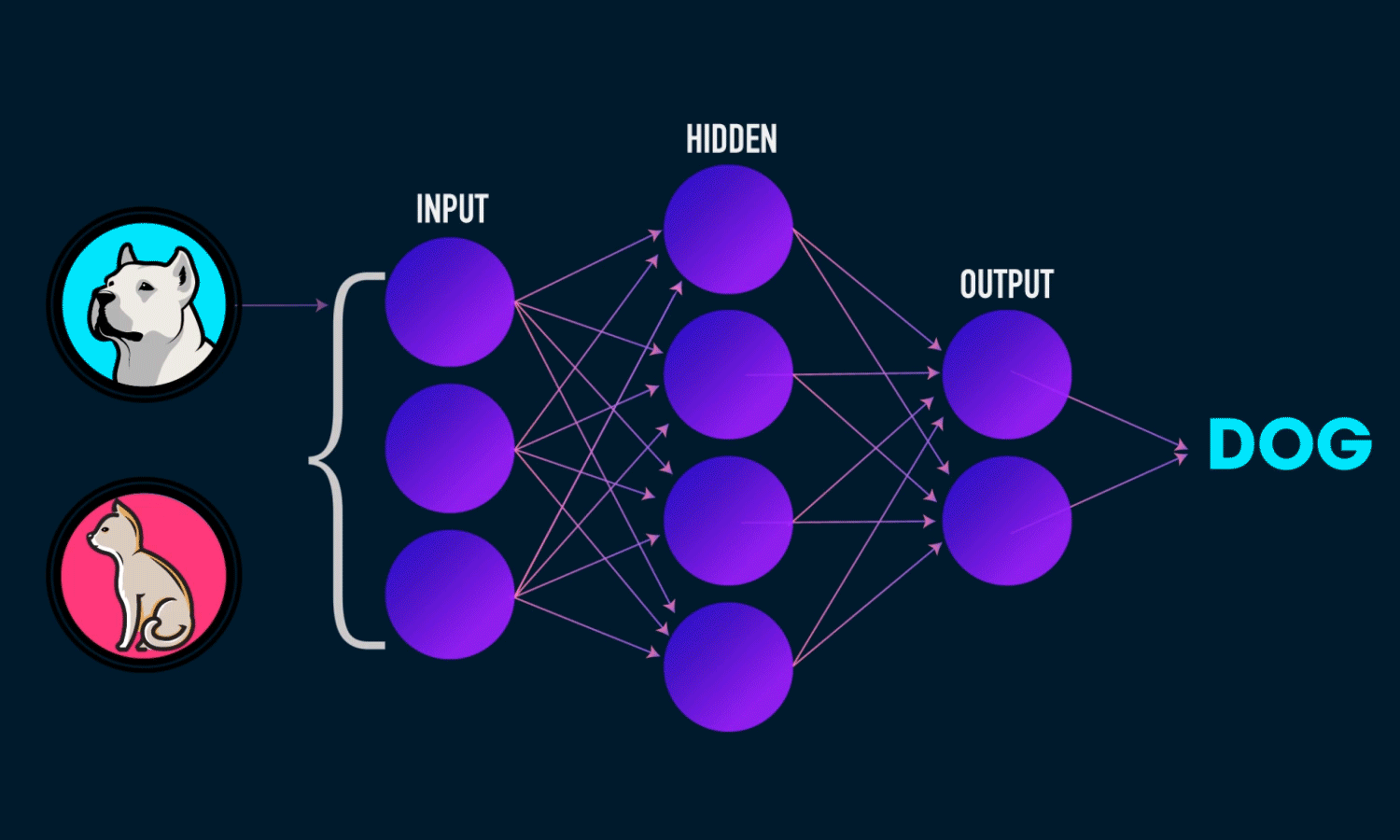
The illustration of how a neural network recognizes a dog in an image. Source: TowardsDataScience
Each layer of nodes trains on the output (feature set) produced by the previous layer. So, nodes in each successive layer can recognize more complex, detailed features – visual representations of what the image depicts. Such a “hierarchy of increasing complexity and abstraction” is known as feature hierarchy.
The Example of feature hierarchy learned by a deep learning model on faces from Lee et al. (2009). Source: ResearchGate.net
So, the more layers the network has, the greater its predictive capability.The leading architecture used for image recognition and detection tasks is Convolutional Neural Networks (CNNs). Convolutional neural networks consist of several layers with small neuron collections, each of them perceiving small parts of an image. The results from all the collections in a layer partially overlap in a way to create the entire image representation. The layer below then repeats this process on the new image representation, allowing the system to learn about the image composition.
The history of deep CNNs dates back to the early 1980s. But only in the 2010s have researchers managed to achieve high accuracy in solving image recognition tasks with deep convolutional neural networks. How? They started to train and deploy CNNs using graphics processing units (GPUs) that significantly accelerate complex neural network-based systems. The amount of training data – photos or videos – also increased because mobile phone cameras and digital cameras started developing fast and became affordable.
Use cases of image recognition
Now you know about image recognition and other computer vision tasks, as well as how neural networks learn to assign labels to an image or multiple objects in an image. Let’s discuss a few real-life applications of this technology.Logo detection in social media analytics
Brands monitor social media text posts with their brand mentions to learn how consumers perceive, evaluate, interact with their brand, as well as what they say about it and why. That’s called social listening. The type of social listening that focuses on monitoring visual-based conversations is called (drumroll, please)... visual listening.The fact that more than 80 percent of images on social media with a brand logo do not have a company name in a caption complicates visual listening. How to gain insights into this case? With logo detection.
Meerkat startup conducted an experiment to show how logo detection can aid visual listening. During the six months, startuppers were collecting tweets with words commonly used in the context of beer, for instance, beer, cerveza, barbecue, bar, and others. They trained a system to detect logos of popular beer brands: Heineken, Budweiser, Corona, Bud Light, Guinness, and Stella Artois. And they used it to analyze images from the tweets containing brand logos.

Heineken logo in different contexts. Source: Meerkat’s Medium
Specialists indexed tweet metadata to gain insights about each brand’s market share and its consumers.First, they compared the number of posts with logos of each brand with their market share and found out that these two parameters aren’t interrelated. Next, specialists extracted geo-coordinates for nearly 73 percent of tweeted images to evaluate brand presence across regions. Then they plotted the percentage of each beer for the top five countries in the dataset. For instance, Bud Light is the most popular in the US, while Heineken has fans in various countries with the biggest shares in the US and UK. The team also analyzed images that contained faces to detect the gender of beer drinkers. The difference was minor: 1.34 percent more men posted the pictures.
It’s not only measuring brand awareness. Businesses are using logo detection to calculate ROI from sponsoring sports events or to define whether their logo was misused.
Medical image analysis
Software powered by deep learning models help radiologists deal with a huge workload of interpreting various medical images: computed tomography (CT) and ultrasound scans, magnetic resonance imaging (MRI), or x-rays. IBM stresses that an emergency room radiologist must examine as many as 200 cases every day. Besides that, some medical studies contain up to 3,000 images. No wonder that medical images account for nearly 90 percent of all medical data.AI-based radiology tools don’t replace clinicians but support their decision-making. They flag acute abnormalities, identify high-risk patients or those needing urgent treatment so that radiologists can prioritize their worklists.
IBM Research division in Haifa, Israel, is working on Cognitive Radiology Assistant for medical image analysis. The system analyzes medical images and then combines this insight with information from the patient's medical records, and presents findings that radiologists can take into account when planning treatment.
Demo for IBM’s Eyes of Watson breast cancer detection tool that uses computer vision and ML. Source: IBM Research
Scientists from this division also developed a specialized deep neural network to flag abnormal and potentially cancerous breast tissue.Aidoc provides another solution that uses deep learning for scanning medical images (CT scans particularly) and prioritizing patient lists. The solution received clearances from the US Food and Drug Administration (FDA), Therapeutic Goods of Australia (TGA), and European Union CE markings for flagging three life-threatening conditions: pulmonary embolism, cervical-spine fracture, and intracranial hemorrhage.
The company clients include UMass Memorial Medical Center in Worcester, Massachusetts, Montefiore Nyack Hospital in Rockland County, NY, and Global Diagnostics Australia, an imaging center.
Apps for recognizing artworks
Magnus is an image recognition-fueled app that guides art lovers and collectors “through the art jungle.” Once a user takes a photo of a piece of art, the app provides such details as author, title, year of creation, dimensions, material, and, most importantly, current and historic price. The app also has a map with galleries, museums, and auctions, as well as currently showcased artworks.Magnus sources information from a database of over 10 million images of artworks; information about pieces and prices is crowdsourced. Interesting fact: Leonardo DiCaprio invested in the app, Magnus says on its Apple Store page.
Museumgoers can satisfy their hunger for knowledge with apps like Smartify. Smartify is a museum guide you can use in dozens of the world’s well-known art spots like The Metropolitan Museum of Art in New York, Smithsonian National Portrait Gallery in Washington DC, the Louvre in Paris, Amsterdam’s Rijksmuseum, the Royal Academy of Arts in London, The State Hermitage Museum in Saint Petersburg, and others.
How Smartify works. Source: Smartify
To reveal details about a piece of art, the app matches scanned artworks against digital images in a database, which contained nearly 50,000 art pieces as of 2017. Smartify co-founder Anna Lowe explains how the app works this way: "We scan artworks using photos or digital images and then create digital fingerprints of the artwork, meaning that it is reduced to a set of digital dots and lines."Facial recognition to improve airport experience
Facial recognition is becoming mainstream among airlines that use it to enhance boarding and check-in. There are two main directions of these upgrades: to follow the trends for self-service and this biometric technology and make the airport experience safer and faster. The fewer steps both passengers and staff must make to proceed with pre-flight routines, the better.Boarding equipment scans travelers' faces and matches them with photos stored in border control agency databases (i.e., U.S. Customs and Border Protection) to verify their identity and flight data. These could be photos from IDs, visas, or other documents.
American Airlines, for instance, started using facial recognition at the boarding gates of Terminal D at Dallas/Fort Worth International Airport, Texas. Instead of using boarding passes, travelers get their face scanned. The only thing that hasn’t changed is that one must still have a passport and a ticket to go through a security check. Biometric boarding works on an opt-in basis.
Biometric boarding for American Airlines passengers. Source: The Dallas Morning News
In 2018, American was testing biometrics for 90 days at Los Angeles International Airport Terminal 4 with the idea of expanding the use of technology if the trial goes well.Numerous airlines implement facial recognition as an extra boarding option as well: JetBlue, British Airways, AirAsia, Lufthansa, or Delta. The last one installed a self-service bag drop at the Minneapolis-St. Paul International Airport in 2017.
Visual product search
Boundaries between online and offline shopping have disappeared since visual search entered the game. For instance, the Urban Outfitters app has a Scan + Shop feature, thanks to which consumers can scan an item they find in a physical store or printed in a magazine, get its detailed description, and instantly order it. Visual search also enhances the online shopping experience.Apps with this capability are powered by neural networks. NNs process images uploaded by users and generate image descriptions (tags), for instance, garment type, fabric, style, color. Image descriptions are matched against items in stock together with their corresponding tags. Search results are presented based on a similarity score.
We dedicated a section about visual search in the article about how retailers use AI. There you can also read about how image and facial recognition technologies have turned cashierless stores like Amazon Go into a reality and also how they power surveillance systems or enable in-store personalization.
The work goes on
In the second part of the 20th century, researchers estimated it would take a relatively short amount of time to solve a computer vision problem, among other things. In 1966, mathematician, and former co-director of MIT Computer Science & AI Lab Seymour Papert was coordinating the Summer Vision Project. The researchers had an ambitious plan: to build a significant part of a system with computer vision capabilities, as we know them today, during one summer. “The primary goal of the project is to construct a system of programs which will divide a vidisector picture into regions such as likely objects, likely background areas, and chaos,” the project description said.Well, it took much longer. Modern software can recognize a large number of everyday objects, human faces, printed and handwritten text in images, and other entities (check out our article on image recognition APIs.) But the work goes on, and we’ll continue witnessing how more and more businesses and organizations implement image recognition and other computer vision tasks to stand out from competitors and optimize operations.