

There are three things that can’t stop expanding: the Universe, Amazon, and the volumes of medical information. While the first two grow thanks to Dark Matter and Jeff Bezos, the third requires HIM — a superpower that turns quantity into quality.
Here, HIM is short for health information management, the discipline too broad to be covered in one article. So, we’ll only touch on its most vital aspects, instruments, and areas of interest — namely, data quality, patient identity, database administration, and compliance with privacy regulations. Finally, we’ll see what to expect from HIM professionals and who can reinforce the HIM superteam.
What is health information management: brief introduction to the HIM landscape
Health information management (HIM) is a set of practices to organize medical data so that it can be effectively used for enhancing the quality of care. It aims at making the right health content accessible whenever it’s required, at the same time ensuring its high quality and security.
The American Health Information Management Association (AHIMA) singles out five functional areas covered by the HIM.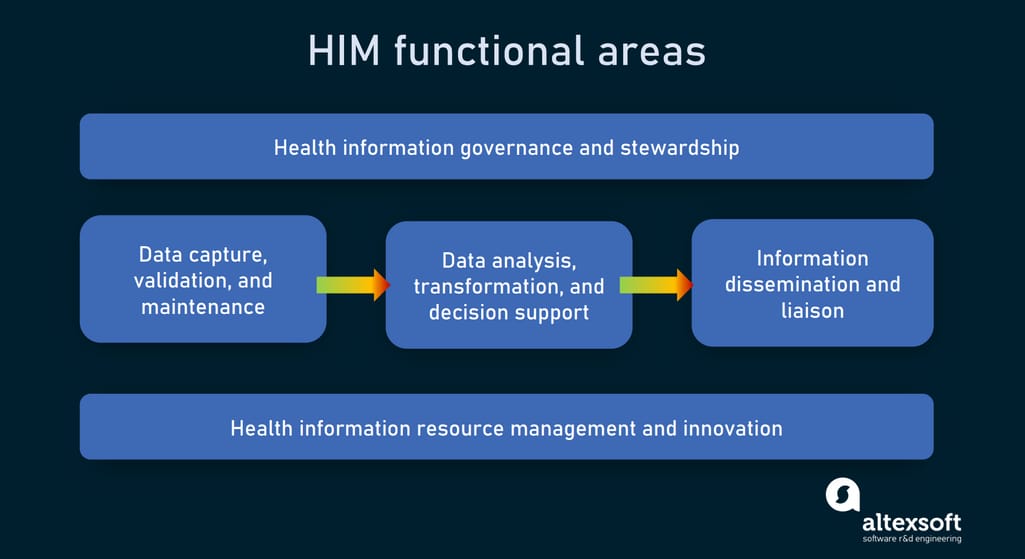
Areas HIM takes care of
Data capture, validation, and maintenance calls for the introduction of policies and procedures to get reliable data. This results in fewer claim denials, decreased operational costs, improved patient safety, and better research outcomes. The stage involves activities related to data quality management, data integration, support for healthcare data standards, and optimum information flow design.
Data analysis, transformation, and decision support revolve around deriving knowledge and insights critical for enhancing patient care.
Information dissemination and liaison are about effective sharing of health records, reports, and research findings.
Health information resource management and innovation take care of health documents across their life cycle.
Health information governance and stewardship ensure compliance of data use with regulations, standards, ethical norms, and internal organizational policies.
HIM practices are applicable wherever health information exists, from private physician’s offices to large hospital chains. But for ultimate clarity, we need to answer the question: What exactly is health information?
Health information vs health data
The terms data and information are often used interchangeably but HIM strictly differentiates them. Data refers to raw facts and figures. By contrast, health information (HI) means knowledge obtained after data is processed and structured into a meaningful form.
Elements like “120/80 blood pressure,” “20 years,” “10/12/21,” and “ John Snow” are just pieces of data. But a resulting record detailing “On October 12, 2021, the blood pressure of 20-year-old John Snow was 120/80” is information that supports patient care and brings value to both healthcare providers and patients.
The specific thing about HI is that more often than not it comes codified. The use of free text to capture diagnoses, procedures, drug data, and other important details can lead to varying interpretations that may disrupt efficient treatment and proper insurance reimbursement.
Medical codes
HI heavily relies on healthcare terminology standards or codes, representing core medical concepts. The industry-specific vocabularies help avoid miscommunications and ambiguity in records.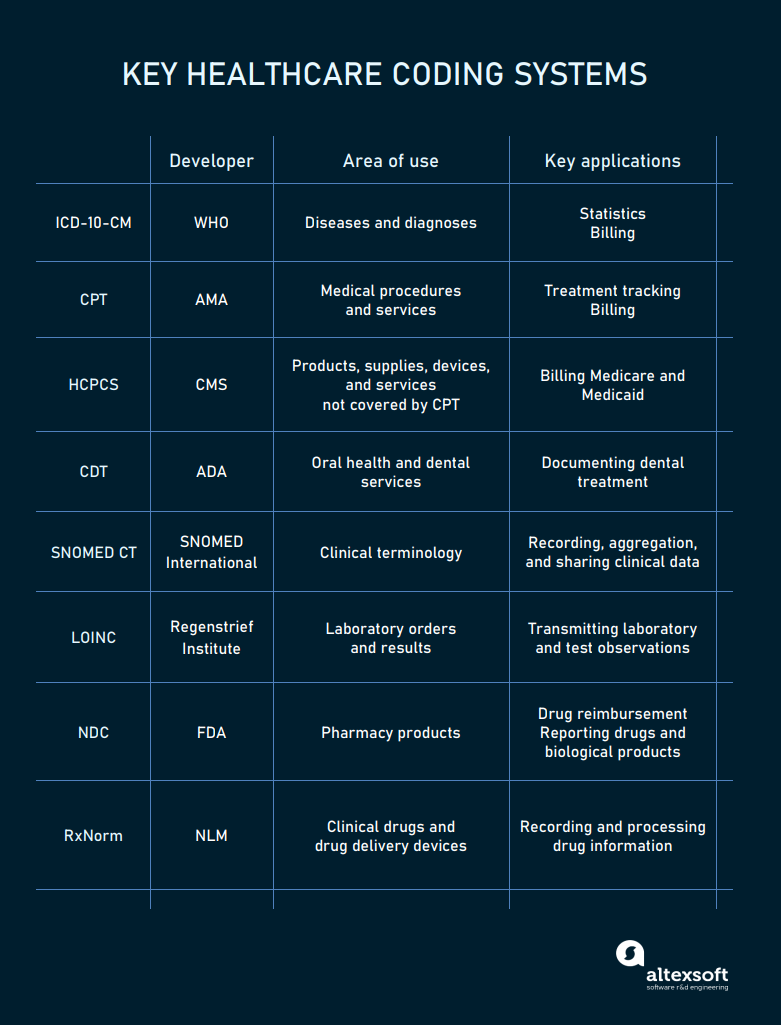
Main coding systems in healthcare
Among the most widespread coding systems are
- ICD-10-CM (the International Classification of Disease, Clinical Modification) for documenting injuries and diagnoses, specifically in medical claims;
- CPT (the Current Procedure Terminology) and HCPS (Healthcare Common Procedure Coding System) for reporting all types of healthcare services, both inpatient and outpatient;
- CDT (Code on Dental Procedures and Nomenclature) for documenting dental treatment;
- SNOMED CT (Systematized Nomenclature of Medicine – Clinical Terms) for capturing symptoms, clinical findings, family history, medical services, drugs, and other aspects related to the course of treatment;
- LOINC (the Logical Observation Identifiers Names and Codes) for recording lab orders/ results and vital signs;
- NDC (National Drug Codes) for pharmacy products; and
- RxNorm for drug classes.
Recorded with codes or as plain text, 85 percent of health information is now kept in digital form across various health information systems.
Health information systems
Health information systems or HISs capture, store, and manage medical information. The heart of the entire HI infrastructure is an electronic health record (EHR) system that handles vital information about patients and their course of treatment.
The list of other widely-spread HISs includes but is by far not limited to
- radiology information systems (RISs),
- laboratory information systems (LISs),
- pharmacy management systems,
- practice management software,
- patient portals,
- medical billing software, and
- remote patient monitoring systems.
To make health systems share information smoothly — and thus enable physicians to build a complete picture of a patient’s health — special exchange standards were developed.
Health information exchange standards and rules
For communication, HISs rely on the following data exchange standards:
ASC (The Accredited Standards Committee) X12, the dominant format of Electronic Data Interchange (EDI.) Developed back in 1979 for transmitting business documentation between machines, EDI still serves a wide range of businesses including healthcare. In particular, X12N specification is used for insurance and reimbursement transactions by third-party payers and government health plans;
HL7 (Health Level Seven) v2 and v2 messages that can be shared via a specific HL7 interface engine; and
FHIR (Fast Healthcare Interoperability Resources), the newest framework created by HL7 specifically for the web. It employs the REST API design, making it possible for third-party apps to access data stored in HISs.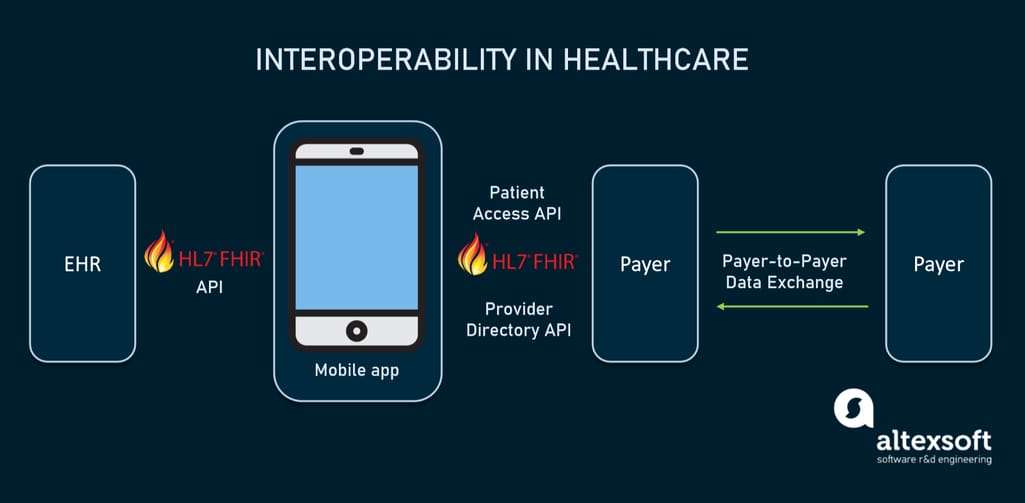
FHIR standard drives interoperability in healthcare
If you’re not familiar with the technological side of data exchange, read the following articles to connect the dots.
According to the final interoperability rules, EHR systems and health plans are obligated to share health information with patients through APIs built on the FHIR standard.
Data elements that must be accessible are defined by another standard called the US Core Data of Interoperability (USCDI.)
USCDI data classes and elements to be accessible via FHIR APIs. Source: FHIM
Now that all key concepts and technologies are in place, we can proceed to major processes within the HIM. In other words, how it contributes to making health information better.
Data quality management
So, data is not the same as information. But the better the quality of the former the higher the value of the latter. Conversely, missing and inaccurate details disrupt the validity of HI, contribute to wrong diagnoses, and lead to incorrect research findings.
To avoid errors that may threaten patient safety, AHIMA introduced the data quality management model which covers
- Application, or the reason for data collection,
- Collection, or the process of data gathering,
- Warehousing, or systems and activities related to data storage and archiving, and
- Analysis, or translating data into meaningful information.
The model also defines ten quality attributes to be applied across all the above-mentioned dimensions.
Health data quality management model by AHIMA
Data quality attributes
By checking your data against these ten traits, you can assess its quality.
Accuracy means that the data is correct and reproduces facts from the source without bias. Say, lab tests must precisely represent results generated by lab equipment.
Accessibility is about the ability of authorized users to easily review medical records whenever required while sticking to privacy regulations.
Comprehensiveness guarantees that the information is complete and the document contains all required data elements. Data can be missed at the collection stage — say, as a result of a data entry error, lack of standardization, or because not all details were taken into consideration during visits. Such gaps may lead to wrong conclusions and lower reliability of insights.
Consistency relates to keeping data uniform and reliable as it moves across applications. For this, all attributes — say, the patient name, age, date of birth, study details, diagnoses, and so on — should be presented in the same format, with the same terminology used.
For example, the date of birth of a particular patient may be registered as 06-11-1982 in one database and as 11-06-1982 in the other. Though this format inconsistency doesn’t pose direct health risks, it can cause doubt about whether both records are related to the same person.
Definition supports data consistency, requiring elements in medical documents to be well-defined and have a range of acceptable values. In other words, users must clearly understand what a particular piece of information describes.
Precision defines a range of values for each attribute. For instance, acceptable values for gender may be F (female), M (male), and U (unknown).
Granularity mirrors the level of detail required for the intended use. Rounding done for numerical values (like body temperature or drug dosage) or peculiarities omitted in the clinical documentation may impact the course of treatment. However, the sufficient granularity level for running administrative tasks can be lower than for diagnostics or research purposes.
Currency ensures that all data is up-to-date and there are no obsolete elements.
Timeliness reflects whether patient information is recorded within a relevant timeframe. Ideally, all important details must be captured at the time of the first visit to a clinic or hospital. New findings, lab results, and other updates are to be added as they become available and as soon as possible.
Relevancy is the term describing the usefulness of data collected. Too lengthy records are often no lesser evil than incomplete documents.
Best practices to ensure data quality
All ten dimensions of data quality are tightly interconnected, so the following recommendations increase the value of the health information as a whole.
Build and maintain medical data dictionaries. A data dictionary is a super catalog of data elements and associated fields, formats, metrics, and values. Among other things, it also contains representations of the same concept across various code systems, possible synonyms, acronyms and even common misspellings. Such a repository allows different apps to share information in the standardized form and eliminates confusion.
Example of a data dictionary. Source: Journal of AHIMA
Note that if your hospital uses a modern database management system to handle information, a dictionary of “data about the data” will be generated automatically.
Take advantage of templates. Most certified EHR systems come with a library of forms for different specialties and types of documentation. As a rule, they can be tailored according to the visit type, allowing for adding and deleting certain fields. Well-arranged templates support standardized data capture and minimize typing.
Implement RPA (Robotic Process Automation) to copy and paste data, fill in forms, and generate reports. This will eliminate human errors. Read our article about healthcare automation to learn how else RPA can help hospitals.
Use computer-assisted coding (CAС) software. CAС tools recognize key words and phrases within a medical document to turn them into relevant codes for billing purposes. While CAС can’t entirely replace humans, it significantly increases the accuracy and productivity of medical coders. Computer-assisted coding is one of the most successful use cases of natural language processing or NLP in healthcare (click on the link to check our recent article on the subject.)
Let’s assume that our data elements meet all the above-mentioned quality criteria. Despite that, it's still not the end of the story. Here, we face the next HIM challenge: How to connect pieces of patient information scattered across different systems together? That’s where the Master Patient Index comes on the scene.
Patient identity management and the Master Patient Index
In simple terms, a Master Patient Index (MPI) also called patient registry is a database that liaises documents related to the same person within a HIS. A more advanced version is the enterprise Master Patient Index (eMPI) that brings together patient documents stored in multiple sources and thus facilitates cross-system information sharing. Yet, the terms are often used synonymously.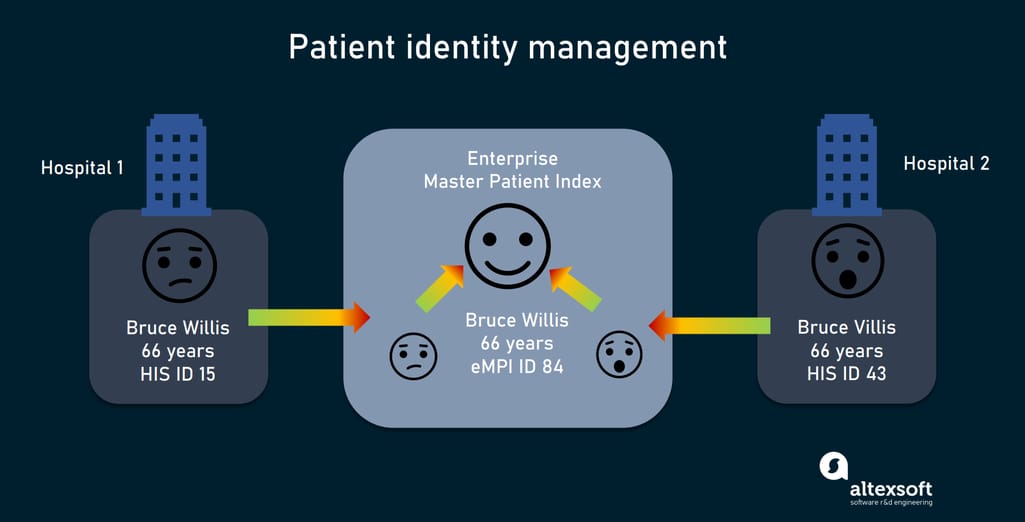
Patient identity management with Enterprise Master Patient Index
The core of the technology is a matching engine that automatically compares data elements within records to determine whether they belong to the same person. If so, the MPI assigns them the same enterprise identifier. It also can find duplicate records and flag them for review.
The MPI ensures patient identification along the care continuum, serving as a single source of truth for all HISs in the network. It generates and stores a so-called golden record per patient with a subset of key data elements such as name, date of birth, demographic details, social security number, and address.
The MPI is an important but by far not the only database within a healthcare facility. Information stored in multiple repositories requires audits, maintenance, updating, and control across its lifecycle. In other words, all things that database management takes care of.
Healthcare database management
Healthcare database management is another crucial component of the HIM that refers to the ability to create, modify, protect, read, and delete data in a given repository.
Modern databases are usually controlled via a database management system (DBMS) that sits between information and the apps consuming it. This separation of concerns allows database administrators or, in the case of healthcare, HIM professionals to alter data without the need to change something in the app code and vice versa.
Here are key parameters that matter when choosing the right DBMS for your health information system.
Security
In the first place, the technology must satisfy strict privacy rules (we’ll talk about them in more detail later in this article). The features to look for in the DBMS are:
- built-in encryption,
- data masking,
- granular access control, and
- sophisticated log audit tools.
So, when choosing between better security and higher performance, prioritize the former over the latter — just to be on the safe side.
Supported data formats
The number one storage option in healthcare is a relational or SQL database that structures data into tables and uses SQL language to manipulate them. MySQL, Maria DB, and other relational DBMSs demonstrate a high level of security and fit most types of medical information, including standardized EHR documents.
Yet, when it comes to storing medical images, electrocardiograms, or fetal strips, an object-oriented database (OOB) offers better performance. It looks like a natural choice for radiology and cardiology departments. On the dark side, OOBs lack a standard query language (like SQL) and universally agreed data models. What's worse, this database doesn’t provide reliable security mechanisms.
There is a happy medium called an object-related database (ORD), that joins the strengths of both above-mentioned candidates. The pure example of the ORD family is PostgreSQL, but other SQL databases such as Oracle, Microsoft SQL Server, and IBM DB2 also support objects.
While relational and ORD approaches still dominate in healthcare, many specialists claim that the future of the industry belongs to NoSQL (or not only SQL) databases. Among the top benefits of such systems are the adoption of various data formats and scalability, which means your HIS will cope with a growing number of users and increased amounts of information.
For now, document-oriented versions of NoSQL (such as MongoDB) with support for JSON and XML formats are viewed as a more advanced alternative for relational counterparts.
Cloud capabilities and HIPAA compliance out of the box
Some large cloud providers offer platforms tailored specifically to store, manage, and share medical records. For example, Azure Healthcare APIs and Healthcare Data Engine by Google support FHIR and other health data exchange standards while ensuring HIPAA compliance. Amazon also possesses tools to build HIPAA-compliant architecture with AWS services. You also can take advantage of resources and schemes for smooth migration of most popular databases to the Amazon cloud.
Security management
Speaking of HI, we can’t omit the subject of regulatory requirements. The lion’s share of medical content belongs to protected health information (PHI) and is secured by the Health Insurance Portability and Accountability Act (HIPAA.) PHI contains personal identifiers that point to particular individuals and can assist with contacting or locating them. Below is the list of 18 data elements HIPAA regards as personal identifiers.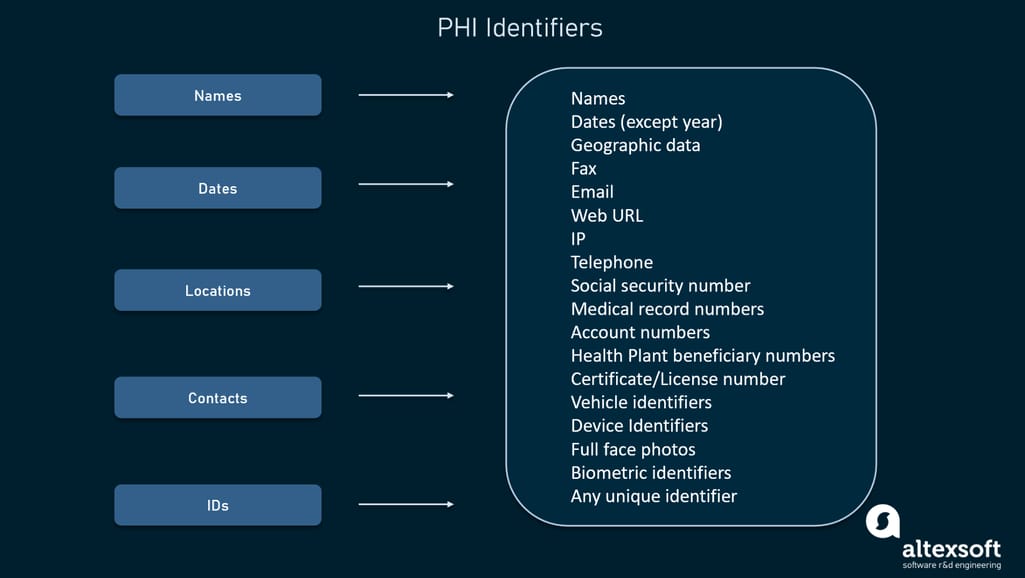
List of data elements that are subject to HIPAA
Eliminating HIPAA violations is one of HIM's major tasks. It outlines several security domains that create a basis for the highest level of data protection across the organization.
Access control prevents unauthorized access to certain information and changing it. It is preceded by authentication — or the process of verifying a visitor’s identity through credentials which at the bare minimum include a user ID and password. Then, the system determines what the user can or can’t do by checking the identity against an access control list (ACL.)
Permission levels can vary across specialists and departments. Say, a physician treating particular patients may view their health records and add new details, but this information remains blocked for other medical workers.
Telecommunication and network security calls for such technical safeguards as firewalls, data encryption in transit and at rest (HIPAA requires end-to-end encryption of PHI), antivirus and antimalware software, automated log-offs, and so on.
Application and system development security promotes the idea that key issues of data protection must be addressed at each stage of the product development process, namely:
- consider the security regulations, policies, and standards when evaluating system feasibility;
- pinpoint threats and vulnerabilities and design a proper level of protection when writing software requirements specifications;
- embed security measures (access controls, encryption, etc.) in product design;
- build security-related features and documentation at the development stage;
- implement security measures and test them against threats before going live; and
- monitor security software and update when necessary.
Operations security (OpSec) is about discovering and addressing overlooked threats in the organization’s daily processes, including the way employees use software and hardware. The routine practices employed by OpSec are
- backing up data in case of an emergency,
- reviewing audit logs to understand who did what in the system and identify inappropriate activities, and
- developing, implementing, and updating security policies.
Physical security refers to the physical protection of the system from different threats including natural disasters, intrusions, fire, and power problems.
Disaster recovery planning dictates steps to be followed if a data breach or loss has occurred. It helps organizations resume work after an unexpected incident as soon as possible.
What is a health information manager?
In the broadest sense, a health information manager develops processes to enhance the quality of documentation, prepares data for further analysis, takes part in managing and maintaining databases, designs privacy and security protection policies, to name just a few responsibilities.
This person needs an in-depth knowledge of system design, information security, legislation, quality assurance, data analytics, and many other disciplines. So having a bachelor’s degree in health informatics or health information management is a must.
But even with the relevant education acquired, one specialist can hardly address all tasks set by HIM. That’s why HIM professionals work under a variety of self-explaining job titles:
- data quality specialist,
- documentation quality coordinator,
- coding trainer,
- healthcare data analyst,
- compliance officer,
- information security manager, and
- many more, depending on the needs of a particular healthcare settings.
Not only certified health information managers can contribute to a common goal — making medical content work for the good of patients. Hospitals and clinics can reinforce their HIM departments with data architects, software developers, quality assurance (QA) engineers, and other tech specialists.
Currently, health information management as a discipline continues expand — this time, towards Big Data and analytics. On this path it may need help from Big Data engineers, data scientists, and other advanced magicians of the digital data universe.