

Various businesses use machine learning to manage and improve operations. While ML projects vary in scale and complexity requiring different data science teams, their general structure is the same. For example, a small data science team would have to collect, preprocess, and transform data, as well as train, validate, and (possibly) deploy a model to do a single prediction.
Netflix data scientists would follow a similar project scheme to provide personalized recommendations to the service's audience of 100 million.
This article describes a common scenario for ML the project implementation. We will talk about the project stages, the data science team members who work on each stage, and the instruments they use.


Roles in data teams, explained
1. Strategy: matching the problem with the solution
In the first phase of an ML project realization, company representatives mostly outline strategic goals. They assume a solution to a problem, define a scope of work, and plan the development. For example, your eCommerce store sales are lower than expected. The lack of customer behavior analysis may be one of the reasons you are lagging behind your competitors.
Several specialists oversee finding a solution.
In this case, a chief analytics officer (CAO) may suggest applying personalization techniques based on machine learning. The techniques allow for offering deals based on customers' preferences, online behavior, average income, and purchase history.
While a business analyst defines the feasibility of a software solution and sets the requirements for it, a solution architect organizes the development. So, a solution architect's responsibility is to make sure these requirements become a base for a new solution. We’ve talked more about setting machine learning strategy in our dedicated article.
Roles: Chief analytics officer (CAO), business analyst, solution architect
2. Dataset preparation and preprocessing
Data is the foundation for any machine learning project. The second stage of project implementation is complex and involves data collection, selection, preprocessing, and transformation.

Data preparation explained in 14 minutes
Each of these phases can be split into several steps.
Data collection
It’s time for a data analyst to pick up the baton and lead the way to machine learning implementation. The job of a data analyst is to find ways and sources of collecting relevant and comprehensive data, interpreting it, and analyzing results with the help of statistical techniques.
The type of data depends on what you want to predict.
There is no exact answer to the question “How much data is needed?” because each machine learning problem is unique. In turn, the number of attributes data scientists will use when building a predictive model depends on the attributes’ predictive value.
‘The more, the better’ approach is reasonable for this phase. Some data scientists suggest considering that less than one-third of collected data may be useful. It’s difficult to estimate which part of the data will provide the most accurate results until the model training begins. That’s why it’s important to collect and store all data — internal and open, structured and unstructured.
The tools for collecting internal data depend on the industry and business infrastructure. For example, those who run an online-only business and want to launch a personalization campaign сan try out such web analytic tools as Mixpanel, Hotjar, CrazyEgg, well-known Google analytics, etc. A web log file, in addition, can be a good source of internal data. It stores data about users and their online behavior: time and length of visit, viewed pages or objects, and location.
Companies can also complement their own data with publicly available datasets. For instance, Kaggle, Github contributors, AWS provide free datasets for analysis.
Roles: data analyst
Data visualization
A large amount of information represented in graphic form is easier to understand and analyze. Some companies specify that a data analyst must know how to create slides, diagrams, charts, and templates.
Stacked bar graph example
Roles: data analyst Tools: Visualr, Tableau, Oracle DV, QlikView, Charts.js, dygraphs, D3.js
Labeling
Supervised machine learning, which we’ll talk about below, entails training a predictive model on historical data with predefined target answers. An algorithm must be shown which target answers or attributes to look for. Mapping these target attributes in a dataset is called labeling.
Data labeling takes much time and effort as datasets sufficient for machine learning may require thousands of records to be labeled. For instance, if your image recognition algorithm must classify types of bicycles, these types should be clearly defined and labeled in a dataset. Here are some approaches that streamline this tedious and time-consuming procedure.
Outsourcing. You can speed up labeling by outsourcing it to contributors from CrowdFlower or Amazon Mechanical Turk platforms if labeling requires no more than common knowledge.
Acquiring domain experts. But in some cases, specialists with domain expertise must assist in labeling. Machine learning projects for healthcare, for example, may require having clinicians on board to label medical tests.
CAPTCHA challenges. Embedding training data in CAPTCHA challenges can be an optimal solution for various image recognition tasks.
Transfer learning. Another approach is to repurpose labeled training data with transfer learning. This technique is about using knowledge gained while solving similar machine learning problems by other data science teams. A data scientist needs to define which elements of the source training dataset can be used for a new modeling task. Transfer learning is mostly applied for training neural networks — models used for image or speech recognition, image segmentation, human motion modeling, etc. For example, if you were to open your analog of Amazon Go store, you would have to train and deploy object recognition models to let customers skip cashiers. Instead of making multiple photos of each item, you can automatically generate thousands of their 3D renders and use them as training data.
Roles: data analyst, data scientist, domain specialists, external contributors
Tools: crowdsourcing labeling platforms, spreadsheets
Data selection
After having collected all information, a data analyst chooses a subgroup of data to solve the defined problem. For instance, if you save your customers’ geographical location, you don’t need to add their cell phones and bank card numbers to a dataset. But purchase history would be necessary. The selected data includes attributes that need to be considered when building a predictive model.
A data scientist, who is usually responsible for data preprocessing and transformation, as well as model building and evaluation, can be also assigned to do data collection and selection tasks in small data science teams.
Roles: data analyst, data scientist
Tools: spreadsheets, MLaaS
Data preprocessing
The purpose of preprocessing is to convert raw data into a form that fits machine learning. Structured and clean data allows a data scientist to get more precise results from an applied machine learning model. The technique includes data formatting, cleaning, and sampling.
Data formatting. The importance of data formatting grows when data is acquired from various sources by different people. The first task for a data scientist is to standardize record formats. A specialist checks whether variables representing each attribute are recorded in the same way. Titles of products and services, prices, date formats, and addresses are examples of variables. The principle of data consistency also applies to attributes represented by numeric ranges.
Data cleaning. This set of procedures allows for removing noise and fixing inconsistencies in data. A data scientist can fill in missing data using imputation techniques, e.g. substituting missing values with mean attributes. A specialist also detects outliers — observations that deviate significantly from the rest of distribution. If an outlier indicates erroneous data, a data scientist deletes or corrects them if possible. This stage also includes removing incomplete and useless data objects.
Data anonymization. Sometimes a data scientist must anonymize or exclude attributes representing sensitive information (i.e. when working with healthcare and banking data).
Data sampling. Big datasets require more time and computational power for analysis. If a dataset is too large, applying data sampling is the way to go. A data scientist uses this technique to select a smaller but representative data sample to build and run models much faster, and at the same time to produce accurate outcomes.
You can read more about data preparation in our dedicated post.
Roles: data scientist
Tools: spreadsheets, automated solutions (Weka, Trim, Trifacta Wrangler, RapidMiner), MLaaS (Google Cloud AI, Amazon Machine Learning, Azure Machine Learning)
Data transformation
In this final preprocessing phase, a data scientist transforms or consolidates data into a form appropriate for mining (creating algorithms to get insights from data) or machine learning. Data can be transformed through scaling (normalization), attribute decompositions, and attribute aggregations. This phase is also called feature engineering.
Scaling. Data may have numeric attributes (features) that span different ranges, for example, millimeters, meters, and kilometers. Scaling is about converting these attributes so that they will have the same scale, such as between 0 and 1, or 1 and 10 for the smallest and biggest value for an attribute.
Decomposition. Sometimes finding patterns in data with features representing complex concepts is more difficult. Decomposition technique can be applied in this case. During decomposition, a specialist converts higher level features into lower level ones. In other words, new features based on the existing ones are being added. Decomposition is mostly used in time series analysis. For example, to estimate a demand for air conditioners per month, a market research analyst converts data representing demand per quarters.
Aggregation. Unlike decomposition, aggregation aims at combining several features into a feature that represents them all. For example, you’ve collected basic information about your customers and particularly their age. To develop a demographic segmentation strategy, you need to distribute them into age categories, such as 16-20, 21-30, 31-40, etc. You use aggregation to create large-scale features based on small-scale ones. This technique allows you to reduce the size of a dataset without the loss of information.
The preparation of data with its further preprocessing is gradual and time-consuming processes. The choice of applied techniques and the number of iterations depend on a business problem and therefore on the volume and quality of data collected for analysis.
Roles: data scientist
Tools: spreadsheets, automated solutions (Weka, Trim, Trifacta Wrangler, RapidMiner), MLaaS (Google Cloud AI, Amazon Machine Learning, Azure Machine Learning)
3. Dataset splitting
A dataset used for machine learning should be partitioned into three subsets — training, test, and validation sets.
Training set. A data scientist uses a training set to train a model and define its optimal parameters — parameters it has to learn from data.
Test set. A test set is needed for an evaluation of the trained model and its capability for generalization. The latter means a model’s ability to identify patterns in new unseen data after having been trained over a training data. It’s crucial to use different subsets for training and testing to avoid model overfitting, which is the incapacity for generalization we mentioned above.
Validation set. The purpose of a validation set is to tweak a model’s hyperparameters — higher-level structural settings that can't be directly learned from data. These settings can express, for instance, how complex a model is and how fast it finds patterns in data.
The proportion of a training and a test set is usually 80 to 20 percent respectively. A training set is then split again, and its 20 percent will be used to form a validation set. At the same time, machine learning practitioner Jason Brownlee suggests using 66 percent of data for training and 33 percent for testing. A size of each subset depends on the total dataset size.
Datasets proportions
The more training data a data scientist uses, the better the potential model will perform. Consequently, more results of model testing data leads to better model performance and generalization capability.
Roles: data scientist
Tools: MLaaS (Google Cloud AI, Amazon Machine Learning, Azure Machine Learning), ML frameworks (TensorFlow, Caffe, Torch, scikit-learn)
4. Modeling
During this stage, a data scientist trains numerous models to define which one of them provides the most accurate predictions.
Model training
After a data scientist has preprocessed the collected data and split it into three subsets, he or she can proceed with a model training. This process entails “feeding” the algorithm with training data. An algorithm will process data and output a model that is able to find a target value (attribute) in new data — an answer you want to get with predictive analysis. The purpose of model training is to develop a model.
Two model training styles are most common — supervised and unsupervised learning. The choice of each style depends on whether you must forecast specific attributes or group data objects by similarities.
Supervised learning. Supervised learning allows for processing data with target attributes or labeled data. These attributes are mapped in historical data before the training begins. With supervised learning, a data scientist can solve classification and regression problems.
Unsupervised learning. During this training style, an algorithm analyzes unlabeled data. The goal of model training is to find hidden interconnections between data objects and structure objects by similarities or differences. Unsupervised learning aims at solving such problems as clustering, association rule learning, and dimensionality reduction. For instance, it can be applied at the data preprocessing stage to reduce data complexity.
Roles: data scientist
Tools: MLaaS (Google Cloud AI, Amazon Machine Learning, Azure Machine Learning), ML frameworks (TensorFlow, Caffe, Torch, scikit-learn)
Model evaluation and testing
The goal of this step is to develop the simplest model able to formulate a target value fast and well enough. A data scientist can achieve this goal through model tuning. That’s the optimization of model parameters to achieve an algorithm’s best performance.
One of the more efficient methods for model evaluation and tuning is cross-validation.
Cross-validation. Cross-validation is the most commonly used tuning method. It entails splitting a training dataset into ten equal parts (folds). A given model is trained on only nine folds and then tested on the tenth one (the one previously left out). Training continues until every fold is left aside and used for testing. As a result of model performance measure, a specialist calculates a cross-validated score for each set of hyperparameters. A data scientist trains models with different sets of hyperparameters to define which model has the highest prediction accuracy. The cross-validated score indicates average model performance across ten hold-out folds.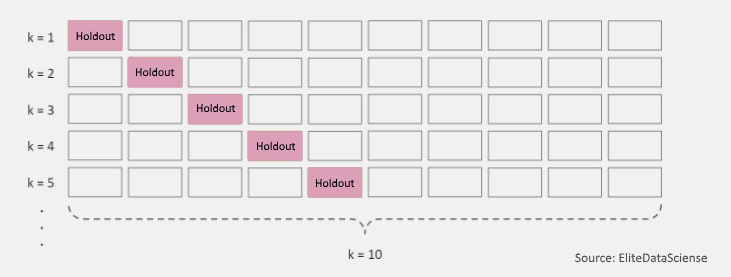
Cross-validation
Then a data science specialist tests models with a set of hyperparameter values that received the best cross-validated score. There are various error metrics for machine learning tasks.
Roles: data scientist
Tools: MLaaS (Google Cloud AI, Amazon Machine Learning, Azure Machine Learning), ML frameworks (TensorFlow, Caffe, Torch, scikit-learn)
Improving predictions with ensemble methods
Data scientists mostly create and train one or several dozen models to be able to choose the optimal model among well-performing ones. Models usually show different levels of accuracy as they make different errors on new data points. There are ways to improve analytic results. Model ensemble techniques allow for achieving a more precise forecast by using multiple top performing models and combining their results. The accuracy is usually calculated with mean and median outputs of all models in the ensemble. Mean is a total of votes divided by their number. Median represents a middle score for votes rearranged in order of size.
The common ensemble methods are stacking, bagging, and boosting.
Stacking. Also known as stacked generalization, this approach suggests developing a meta-model or higher-level learner by combining multiple base models. Stacking is usually used to combine models of different types, unlike bagging and boosting. The goal of this technique is to reduce generalization error.
Bagging (bootstrap aggregating). This is a sequential model ensembling method. First, a training dataset is split into subsets. Then models are trained on each of these subsets. After this, predictions are combined using mean or majority voting. Bagging helps reduce the variance error and avoid model overfitting.
Boosting. According to this technique, the work is divided into two steps. A data scientist first uses subsets of an original dataset to develop several averagely performing models and then combines them to increase their performance using majority vote. Each model is trained on a subset received from the performance of the previous model and concentrates on misclassified records.
A model that most precisely predicts outcome values in test data can be deployed.
Roles: data scientist
Tools: MLaaS (Google Cloud AI, Amazon Machine Learning, Azure Machine Learning), ML frameworks (TensorFlow, Caffe, Torch, scikit-learn)
5. Model deployment
The model deployment stage covers putting a model into production use.
Once a data scientist has chosen a reliable model and specified its performance requirements, he or she delegates its deployment to a data engineer or database administrator. The distribution of roles depends on your organization’s structure and the amount of data you store.
A data engineer implements, tests, and maintains infrastructural components for proper data collection, storage, and accessibility. Besides working with big data, building and maintaining a data warehouse, a data engineer takes part in model deployment. To do so, a specialist translates the final model from high-level programming languages (i.e. Python and R) into low-level languages such as C/C++ and Java. The distinction between two types of languages lies in the level of their abstraction in reference to hardware. A model that's written in low-level or a computer’s native language, therefore, better integrates with the production environment.
After translating a model into an appropriate language, a data engineer can measure its performance with A/B testing. Testing can show how a number of customers engaged with a model used for a personalized recommendation, for example, correlates with a business goal.
When it comes to storing and using a smaller amount of data, a database administrator puts a model into production.
Deployment workflow depends on business infrastructure and a problem you aim to solve. A predictive model can be the core of a new standalone program or can be incorporated into existing software.
Model productionalization also depends on whether your data science team performed the above-mentioned stages (dataset preparation and preprocessing, modeling) manually using in-house IT infrastructure and or automatically with one of the machine learning as a service products.
Machine learning as a service is an automated or semi-automated cloud platform with tools for data preprocessing, model training, testing, and deployment, as well as forecasting. The top three MLaaS are Google Cloud AI, Amazon Machine Learning, and Azure Machine Learning by Microsoft. ML services differ in a number of provided ML-related tasks, which, in turn, depends on these services' automation level.
Deployment on MLaaS platforms is automated. For example, the results of predictions can be bridged with internal or other cloud corporate infrastructures through REST APIs. You should also think about how you need to receive analytical results: in real-time or in set intervals.
Batch prediction
This deployment option is appropriate when you don’t need your predictions on a continuous basis. When you choose this type of deployment, you get one prediction for a group of observations. A model is trained on static dataset and outputs a prediction. You can deploy a model on your server, on a cloud server if you need more computing power or use MlaaS for it. Deployment is not necessary if a single forecast is needed or you need to make sporadic forecasts. For example, you can solve classification problem to find out if a certain group of customers accepts your offer or not.
Web service
Such machine learning workflow allows for getting forecasts almost in real time. A model however processes one record from a dataset at a time and makes predictions on it. It’s possible to deploy a model using MLaaS platforms, in-house, or cloud servers.
Real-time prediction (real-time streaming or hot path analytics)
This type of deployment speaks for itself. With real-time streaming analytics, you can instantly analyze live streaming data and quickly react to events that take place at any moment. Real-time prediction allows for processing of sensor or market data, data from IoT or mobile devices, as well as from mobile or desktop applications and websites. As this deployment method requires processing large streams of input data, it would be reasonable to use Apache Spark or rely on MlaaS platforms. Apache Spark is an open-source cluster-computing framework. A cluster is a set of computers combined into a system through software and networking. Due to a cluster’s high performance, it can be used for big data processing, quick writing of applications in Java, Scala, or Python.
Web service and real-time prediction differ in amount of data for analysis a system receives at a time.
Stream learning
Stream learning implies using dynamic machine learning models capable of improving and updating themselves. You can deploy a model capable of self learning if data you need to analyse changes frequently. Apache Spark or MlaaS will provide you with high computational power and make it possible to deploy a self-learning model.
Roles: data architect, data engineer, database administrator
Tools: MlaaS (Google Cloud AI, Amazon Machine Learning, Azure Machine Learning), ML frameworks (TensorFlow, Caffe, Torch, scikit-learn), open source cluster computing frameworks (Apache Spark), cloud or in-house servers
Conclusion
Regardless of a machine learning project’s scope, its implementation is a time-consuming process consisting of the same basic steps with a defined set of tasks. The distribution of roles in data science teams is optional and may depend on a project scale, budget, time frame, and a specific problem. For instance, specialists working in small teams usually combine responsibilities of several team members.
Even though a project’s key goal — development and deployment of a predictive model — is achieved, a project continues. Data scientists have to monitor if an accuracy of forecasting results corresponds to performance requirements and improve a model if needed. Make sure you track a performance of deployed model unless you put a dynamic one in production. One of the ways to check if a model is still at its full power is to do the A/B test. Performance metrics used for model evaluation can also become a valuable source of feedback. The faster data becomes outdated within your industry, the more often you should test your model’s performance.