

This article explores NoSQL databases, their types, and use cases, explaining how they differ from relational databases, and providing an overview of the most popular tools for storing non-tabular data.
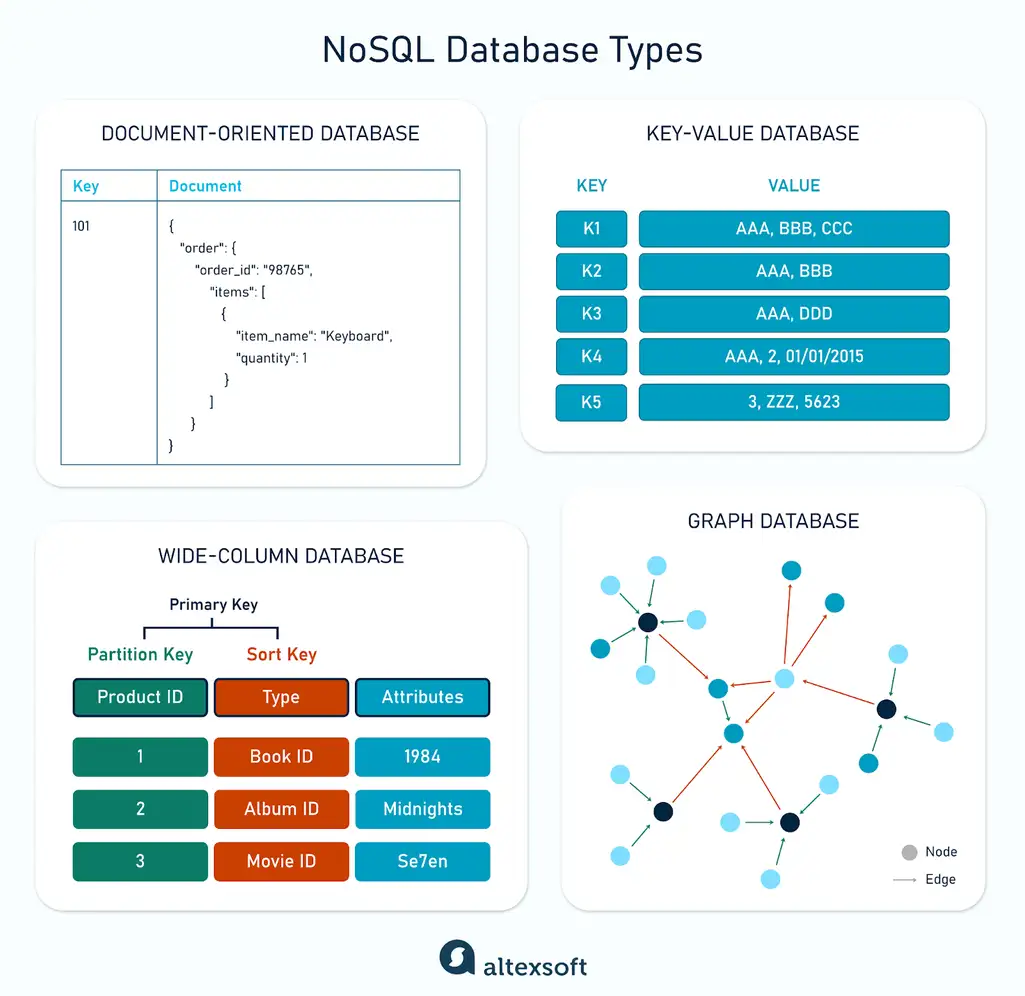
NoSQL database types
What is a NoSQL database?
NoSQL or non-relational databases are storage systems designed to keep and manage large volumes of data in non-tabular formats. Though they can support structured data, the strength of NoSQL databases lies in handling a variety of data types (including semi-structured or unstructured data) in flexible, schemaless formats.
NoSQL databases support horizontal scalability, which means increasing the capacity by adding more servers (or nodes) rather than upgrading the resources of a single server, known as vertical scaling. The ability to distribute workloads across multiple machines is critical for handling massive amounts of data while maintaining acceptable performance. That’s why NoSQL databases are commonly used for big data analytics, IoT (Internet of Things) apps, and content management systems (CMS).
Relational SQL database vs. NoSQL database
Both relational and NoSQL databases are essential in modern data management, but they cater to different needs. The table below compares their key attributes side by side.

Relational SQL databases vs. NoSQL databases
Relational or SQL databases organize and store data in a highly structured way, using tables, which are made up of rows (entries or records) and columns (categories or attributes of the data). For example, a table about customers might have columns for names, emails, phone numbers, and addresses, with each row representing one unique customer.

An example of a relational database
Relationships between tables are created using special identifiers called keys.
- A primary key (PK) is a unique identifier for each row in a table (e.g., a Customer ID).
- A foreign key (FK) is a column in one table that refers to the primary key in another table, linking the data across tables.
Relational databases support ACID (Atomicity, Consistency, Isolation, Durability) properties that guarantee data accuracy and consistency even in cases of system failure.
- Atomicity ensures that all operations within a transaction are treated as a single unit—if one operation fails, the entire transaction fails.
- Consistency ensures that transactions adhere to the rules of the database and brings them from one valid state to another.
- Isolation ensures that transactions are processed independently of each other.
- Durability ensures that once a transaction is completed, it will persist even in the event of a system crash.

ACID properties
ACID provides strong consistency and transactional integrity, making relational databases ideal for applications like customer relationship management (CRM) or banking systems.
NoSQL databases prioritize performance and scalability, sacrificing strict ACID compliance for eventual consistency. This means data might not be updated across all nodes immediately, but after a bit will sync to the most recent state. For example, this approach perfectly fits social media apps, where availability is more critical than immediate consistency. However, some NoSQL databases may support ACID properties in specific contexts.
NoSQL database types
There are four main NoSQL database types: key-value, document, graph, and column-oriented (wide-column). Each of them is designed to address specific challenges and use cases, as different applications demand different ways of organizing and querying data. For example, some applications prioritize speed and simplicity, while others need to represent complex relationships or process massive amounts of real-time data.

NoSQL database types
In the following sections, we’ll break down NoSQL database types, including their elements and capabilities, use cases, and the most popular systems in each category.

Most popular NoSQL databases
Key-value databases: Redis, Memcached, RocksDB, Hazelcast, Valkey
As the name suggests, key-value databases store data as pairs of keys and values. Each key is a unique identifier (like a name, ID, or reference number) and is associated with a value, which can be anything from a simple string to a more complex data structure, such as an object or a list.

Key-value database
To retrieve data, the database management system looks up the value using the associated key. For example, you request the value for "K2." The database applies a hash function to that key, retrieves the value from the computed location, and returns the value "AAA, BBB."
Key-value databases are optimized for fast, efficient, and simple lookups by key, but they are limited when it comes to complex query operations. For example, you can’t filter the values based on attributes like “find all users with ages greater than 30” because the system only stores and retrieves data based on the unique key.
Key-value database use cases
Key-value databases excel due to their flexibility and speed in various scenarios.

Key-value database use cases
Performance monitoring. For example, in ad performance metrics, each ad has a unique key with values containing data like impressions, clicks, and conversions. As users interact with the ad, these metrics are updated in real time. The system can quickly retrieve metrics for any ad, allowing advertisers to monitor performance and optimize campaigns accordingly.
Storing basic information. Key-value databases are a straightforward solution for applications requiring simple data storage without complex relationships. For example, an eCommerce website can store shopping cart data, where the key is the user ID, and the value is the cart's content.
Session management and caching. Key-value databases ensure quick access and updates for user session details such as authentication tokens, preferences, or temporary states. In a video streaming service, session data like user authentication status and current playback position can be stored and retrieved instantly, even for millions of active users.
Video game boards. Multiplayer online games require real-time tracking of player sessions, including scores, in-game items, and progress. Each player's session is stored with the player ID as the key and session data (e.g., location, health, inventory) as the value.
IoT applications. IoT applications generate time-stamped data that can be stored in a key-value database for efficient time-series analysis. For example, a smart thermostat streams temperature readings with timestamps as keys, enabling quick retrieval for analytics purposes—like generating usage insights or predictions.
Most popular key-value databases
Redis is an open-source, in-memory key-value database often used for caching, session management, and real-time analytics. It supports complex data types (for example, strings, hashes, lists, sets, sorted sets, and JSON).
Redis offers built-in replication, meaning that data from the primary (master) instance is automatically copied to one or more secondary (replica) instances. It also provides various levels of protecting data from loss, such as logging every write operation in a sequential file that can be replayed to restore the exact state before the crash.
Memcached is a simple in-memory key-value store designed to improve application response times by caching small pieces of data, such as strings or objects.
RocksDB is an embeddable persistent key-value store that supports basic operations (reading and writing data) and advanced tasks like merging (combining new and existing data) and compaction filters (defining custom rules for how data should be merged or discarded).
Hazelcast is a unified real-time data platform that combines data ingestion, stream processing, and fast data store. It integrates into application environments, whether deployed on-premises or in the cloud.


Data Streaming, Explained
Valkey is an open-source store supporting workloads like caching and message queues. It can serve as a primary database, running as a standalone process or in a cluster setup. Valkey includes built-in Lua (a lightweight programming language) scripting, allowing users to extend its functionality with custom logic. It also supports modular plugins, enabling developers to create new commands, data types, and additional features tailored to their needs.
Document databases: MongoDB, Apache CouchDB, Firebase Firestore, Amazon DocumentDB
Document databases store, manage, and retrieve data in the form of documents (in JSON, BSON, or XML formats). Each document is identified by a unique key (similar to the key in a key-value store) and contains relevant information about a particular entity (for example, product order). Data within each document can be organized in nested fields, arrays, and other structures.

An example of a JSON-formatted document
Documents have no pre-defined schema, allowing for flexibility in how data is represented.
For example, in an SQL database, a "patients" table would require all records to have the same columns, such as "name," "age," and "address." In a document, each patient's record can be customized—some may include additional fields like "allergies" or "ongoing treatments."
Document databases allow you to query information not just by the unique identifier (like the key in key-value databases) but also by the internal content. You can apply conditions or filters to your queries. For example, you can find all users within a certain age group or of a certain status.
Document databases also support aggregation operations (calculating, grouping, and summarizing data) and indexing (locating and retrieving documents based on the indexed fields).
Document database use cases
Since documents are flexible in terms of structure, they are particularly suited to applications that need to evolve over time, as new fields can be added without affecting existing data.

Document database use cases
Content Management Systems (CMS). Document databases allow for the storage of various content types and metadata. Each piece of content (e.g., blog post, article, or media file) can be stored as a document.
User profiles. Document databases allow nesting, enabling you to store hierarchical or grouped data within a single document. This makes it easy to model complex user profiles that include details like order histories, preferences, or social connections.
Cataloging. Document databases are useful in systems that must catalog items with varied attributes, such as inventory management for a large organization. Each item can be stored as a document with its own set of attributes (e.g., product name, quantity, price), making it easier to update and scale as inventory grows.
Most popular document databases
MongoDB is one of the most widely used document databases. It stores data in BSON format and supports powerful queries (e.g., filtering on deeply nested data) and indexing capabilities (e.g., indexing individual or multiple fields in a collection or making documents expire after a specified time). It is a popular option for web and mobile applications with large and dynamic datasets.
Apache CouchDB relies on JSON format and is known for its robust replication features. It is used in environments where data needs to be synchronized in multiple instances, including across geographically distributed server clusters, mobile devices, and web browsers. The replication protocol enables an offline-first approach, meaning that data can be stored locally and synced when the device is back online.
Firebase Firestore is built on Google Cloud infrastructure for mobile, web, and server-side development. It automatically syncs data between client apps and offers offline functionality for mobile and web apps. Firestore integrates with other Firebase and Google Cloud services.
Amazon DocumentDB (with MongoDB compatibility) is a JSON document database that offers built-in security, continuous backups, and integrations with other AWS services. To enhance your applications, you can leverage advanced capabilities such as generative AI and machine learning, which are available due to the integration with Amazon SageMaker Canvas.
Graph databases: Neo4j, Amazon Neptune, JanusGraph
Graph databases are designed to store, manage, and query data in the form of graphs that consist of nodes and edges.

Graph database
Here's a breakdown of graph components.
- Nodes (or vertices) represent entities (e.g., people, products, locations).
- Edges are the relationships between nodes (e.g., "friend with," "purchased from," "located at").
- Properties store additional information (e.g., a "friend with" relationship could have a "since" property to indicate when the relationship was established).
In graph databases, the relationships between data are as important as the data itself. That’s why both the nodes and the edges have properties, allowing the database to represent complex relationships between data points.
One of the key features of graph databases is their ability to efficiently traverse relationships between nodes. For example, if you want to find all users who are friends of friends of a particular user, a graph database will allow you to follow the "friendship" edges. A query will start at one node and follow a chain of relationships to reach other connected nodes.
Graph database use cases
Graph databases excel at managing highly interconnected data and allow for intuitive, flexible queries, making them powerful for modern applications involving complex relationships.

Graph database use cases
Social networks. Graph databases are commonly used in social networking platforms, where users are connected to other users through relationships like "follower" or "message sender." Graph databases make it easy to query for friends of friends, mutual connections, or any other complex social relationship.
Recommender systems. Products, movies, or services can be traced to users through relationships like "purchased" or "watched," and the system can recommend items based on the connections and similarities between users and products.
Fraud detection. Graph databases are powerful tools for fraud detection because they focus on analyzing relationships between entities such as people, accounts, and transactions. They can identify patterns and anomalies that suggest fraudulent activities, such as uncovering circular money movements used in money laundering or unusual relationships between accounts.
Natural language processing (NLP). Graph databases store complex relationships and connections in data, such as links between words in a sentence—words can be represented as nodes, with edges showing relationships like syntactic structure (subject-verb-object) or semantic meaning (synonyms or contextual associations).
Natural language processing models can leverage graph databases to better understand word relationships and improve tasks like sentiment analysis, entity recognition, or translation.
Most popular graph databases
Neo4j offers a cloud-ready architecture that can be deployed in self-hosted, hybrid, multi-cloud, or fully managed environments like Neo4j AuraDB. The Cypher Parallel Runtime feature enables fast processing of complex queries by running them in parallel.
Amazon Neptune includes built-in security features and automatically backs up data to ensure its durability and protection. It integrates with other AWS services and enables cross-region data replication, ensuring low-latency reads and writes for globally distributed applications. Neptune can scale graphs with unlimited nodes and edges and handle more than 100,000 queries per second.
JanusGraph is optimized for storing and querying graphs that contain hundreds of billions of nodes and edges distributed across a multi-machine cluster. It supports reliable data transactions that adhere to ACID properties. JanusGraph can handle thousands of concurrent users who are executing complex graph traversals in real time.
Column-oriented or wide-column databases: Apache Cassandra, Apache HBase, Apache Druid, ScyllaDB
Сolumn-oriented (or wide-column) databases store data column by column rather than rows, organizing related information in column families. Unlike SQL databases, the structure of these columns doesn’t have to be consistent across rows. Each row within a family can have a completely different number of columns. This flexibility allows column-oriented databases to handle large amounts of data with varying schemas.

Wide-column database
From the image above, the data is organized as follows.
- "1" is the partition key, which uniquely identifies the row.
- "Book ID" is the sort key, which organizes data within a partition.
- "1984," “George Orwell,” and “1949” are attributes that store additional data associated with the row. A new attribute or column can be added to a row without requiring all rows to include it.
Wide-column databases support complex queries like filtering, grouping, and aggregating over massive datasets with millions or billions of rows.
Column-oriented (wide-column) database use cases
Column-oriented databases are particularly useful in analytical and large-scale applications.

Column-oriented (wide-column) database use cases
IoT systems. The massive volume of data generated by IoT devices, such as sensor readings and telemetry, is often stored in column-oriented databases. They can efficiently handle the high-write throughput and effectively store streaming data like temperature, humidity, and device statuses. Column-oriented databases also fit scenarios when you need to monitor manufacturing equipment and run predictive maintenance.
Big data analytics and BI tools. By storing data in columns, queries can focus on specific sets of data, minimizing the amount of irrelevant information that must be read and making analytical queries faster and more efficient. For example, if you want to calculate the total sales per region, only the "sales" and "region" columns have to be accessed.
BI queries (e.g., in data warehousing) typically focus on analyzing specific metrics across a dataset, such as calculating sales trends or profitability. Here, similarly, the database only reads the columns involved in the query and avoids accessing irrelevant data.
Most popular column-oriented (wide-column) databases
Apache Cassandra is a free, open-source database designed to manage large amounts of distributed data. If a node fails, Cassandra replaces it without causing downtime, ensuring that the application remains operational. It also supports data replication throughout multiple data centers, ensuring that data is available even in the event of a regional outage.
Apache HBase, modeled after Google's Bigtable, automatically divides tables into smaller units called "regions," which are distributed over multiple servers. It is built on top of Hadoop and provides a Java API for client applications to interact with the database.
Apache Druid is designed for real-time analytics and OLAP (Online Analytical Processing) workloads for complex querying and reporting. Its native integrations with streaming platforms like Apache Kafka and Amazon Kinesis allow it to ingest streaming data in real time with low latency and ensure consistency, enabling query-on-arrival for millions of events per second.
ScyllaDB is compatible with Cassandra and mostly used for real-time data processing, IoT applications, and time-series analysis. ScyllaDB benefits from a shared-nothing architecture (where each node operates independently), automatic data partitioning, and tunable consistency that allows users to configure how strictly the system enforces a particular structure.
Multi-model databases: Amazon DynamoDB, Couchbase, Azure Cosmos DB, ArangoDB
Multi-model databases support different ways of storing data (document, key-value, graph, and wide-column) within the same system. They allow applications to store data in the most convenient form, handling only one repository. For example, user data can be kept as documents and relations as graphs.
Amazon DynamoDB supports document and key-value models. It includes reliability features, such as managed backups (automatically or semi-automatically backing up data at scheduled intervals), point-in-time recovery (restoring a database to a specific moment in time), and more.
Couchbase combines the functionality of a document and key-value store with built-in operational and analytical capabilities. It supports SQL++ (an extended version of SQL) querying and ACID transactions. Couchbase integrates with search and analytics engine Elasticsearch, BI tools Power BI and Tableau, a streaming service Apache Kafka, and Apache Spark used for big data analytics.
ArangoDB embraces graph, document, and key-value data models. It supports Docker and orchestration with Kubernetes allowing you to easily set up and deploy the database in isolated containers. ArangoDB offers a unified query language, AQL (ArangoDB Query Language), designed to be user-friendly for those familiar with SQL.
Azure Cosmos DB supports storing data in documents, key-value pairs, wide columns, and graphs. It’s compatible with MongoDB and Apache Cassandra and supports Apache Gremlin for querying graph data. It also allows for querying JSON data with an SQL-like language.

Linda is a tech journalist at AltexSoft, specializing in travel technologies. With a focus on this evolving industry, she analyzes and reports on the technologies and latest tech that influence the world of travel. Beyond the professional domain, Linda's passion for writing extends to novels, screenplays, and even poetry.
Want to write an article for our blog? Read our requirements and guidelines to become a contributor.