Imagine you’re completing a mission in a computer game. Maybe you’re going through a military depot to find a secret weapon. You get points for the right actions (killing an enemy) and lose them for the wrong ones (falling into a pit or getting hit). If you’re playing on high difficulty, you might not conclude this task in just one attempt. Try after try, you learn which consecutive actions are needed to get out of a location safe, armed, and equipped with bonuses like extra health points or small artifacts in your bag. Every time you challenge yourself and compete with other gamers in the virtual world, you act as a reinforcement learning agent.
In this article, we’ll talk about the core principles of reinforcement learning and discuss how industries can benefit from implementing it.
What is reinforcement learning?
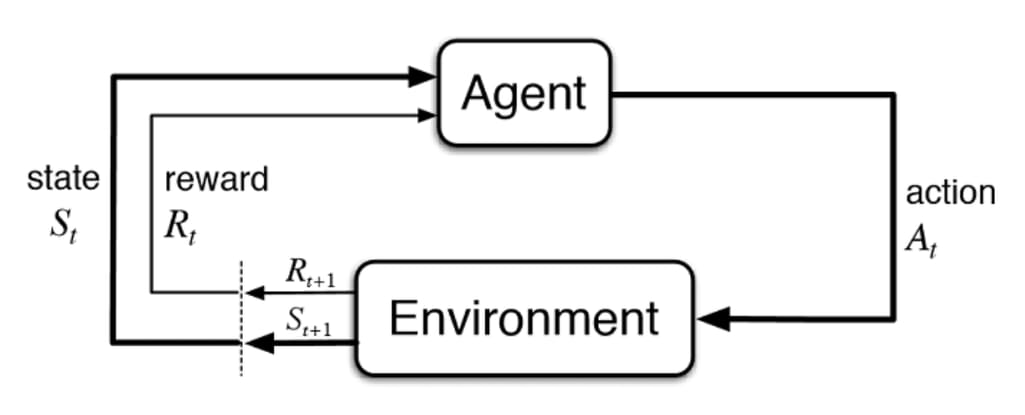
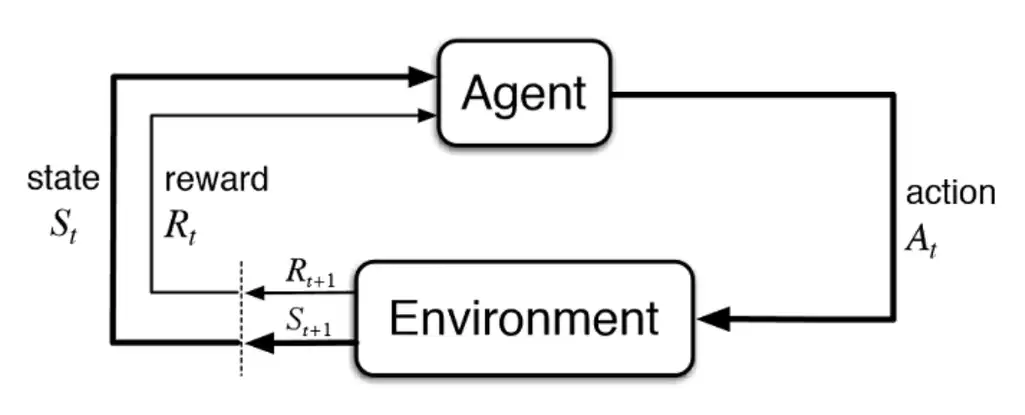
Reinforcement learning (RL) is a machine learning technique that focuses on training an algorithm following the cut-and-try approach. The algorithm (agent) evaluates a current situation (state), takes an action, and receives feedback (reward) from the environment after each act. Positive feedback is a reward (in its usual meaning for us), and negative feedback is punishment for making a mistake.
RL algorithm learns how to act best through many attempts and failures. Trial-and-error learning is connected with the so-called long-term reward. This reward is the ultimate goal the agent learns while interacting with an environment through numerous trials and errors. The algorithm gets short-term rewards that together lead to the cumulative, long-term one.
So, the key goal of reinforcement learning used today is to define the best sequence of decisions that allow the agent to solve a problem while maximizing a long-term reward. And that set of coherent actions is learned through the interaction with environment and observation of rewards in every state.
Difference between reinforcement learning, supervised learning, and unsupervised learning
Reinforcement learning is distinguished from other training styles, including supervised and unsupervised learning, by its goal and, consequently, the learning approach.
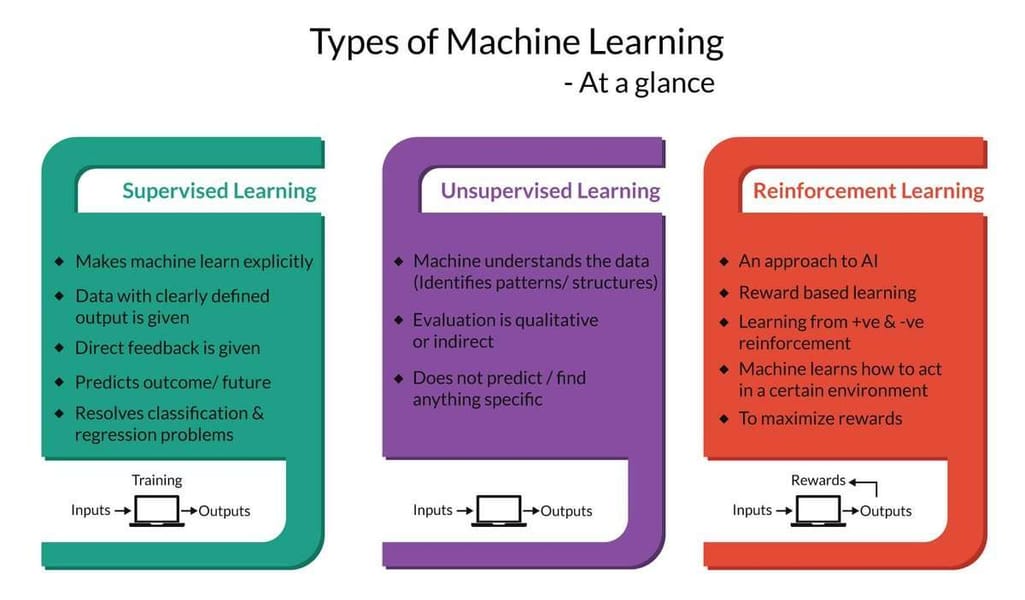
Reinforcement learning vs supervised learning. In supervised learning, an agent “knows” what task to perform and which set of actions is correct. Data scientists train the agent on historical data with target variables (desired answers with predictive analysis) AKA labeled data. The agent receives direct feedback. As a result of training, an agent can forecast whether there will be target variables in new data or not. Supervised learning allows for solving classification and regression tasks.
Reinforcement learning doesn’t rely on labeled datasets: The agent isn’t told which actions to take or the optimal way of performing a task. RL uses rewards and penalties instead of labels associated with each decision in datasets to signal whether a taken action is good or bad. So, the agent only gets feedback once it completes the task. That’s how time-delayed feedback and the trial-and-errorprinciple differentiate reinforcement learning from supervised learning.
Since one of the goals of RL is to find a set of consecutive actions that maximize a reward, sequential decision making is another significant difference between these algorithm training styles. Each agent’s decision can affect its future actions.
Reinforcement learning vs unsupervised learning. In unsupervised learning, the algorithm analyzes unlabeled data to find hidden interconnections between data points and structures them by similarities or differences. RL aims at defining the best action model to get the biggest long-term reward, differentiating it from unsupervised learning in terms of the key goal.
Reinforcement and deep learning. Most of reinforcement learning implementations employ deep learning models. They involve the use of deep neural networks as the core method for agent training. Unlike other machine learning methods, deep learning fits best for recognizing complex patterns in images, sounds, and texts. Additionally, neural networks allow data scientists to fit all processes into a single model without breaking down the agent’s architecture into multiple modules.
Reinforcement learning use cases
Reinforcement learning is applicable in numerous industries, including internet advertising and eCommerce, finance, robotics, and manufacturing. Let’s take a closer look at these use cases.
Personalization
News recommendation. Machine learning has made it possible for businesses to personalize customer interactions at scale through the analysis of data on their preferences, background, and online behavior patterns.
However, recommending such content type as online news is still a complex task. News features are dynamic by nature and become rapidly irrelevant. User preferences in topics change as well.
Authors of the research paper DRN: A Deep Reinforcement Learning Framework for News Recommendation discuss three main challenges related to news recommendation methods. First, these methods only try to model current (short-term) reward (e.g., click-through rate that shows the ratios page/ad/email viewers that click on a link). The second issue is that current recommendation methods usually take into account the click/no click labels or ratings as users’ feedback. And third, these methods typically continue suggesting similar news to readers, so users can get bored.
The researchers used the Deep Q-Learning based recommendation framework that considers current reward and future reward simultaneously in addition to user return as feedback rather than clicks data.
Games personalization. Gaming companies also have joined the personalization party. Really, why not tailor a video game experience (rules and content) taking into account an individual player’s skill level, playing style, or preferred gameplay? Personalization of game experience is done through player modeling with the goal of increasing their enjoyment. A player model is an abstract description of a player based on their behavior in a game.
Game components that can be adapted include space, mission, character, narrative, music and sound, game mechanics, difficulty scaling, and player matching (in multiplayer games).
Unity provides an ML toolset for researchers and developers that allows for training intelligent agents with reinforcement learning and “evolutionary methods via a simple Python API.”
It’s worth mentioning that we haven't found any application of RL agents in production.
eCommerce and internet advertising
Specialists are experimenting with reinforcement learning algorithms to solve a problem of impressions allocation on eCommerce sites like eBay, Taobao, and Amazon. Impressions refer to the number of times a visitor sees some element of a web page, an ad or a product link with a description. Impressions are often used to calculate how much an advertiser has to pay to show his message on a website. Each time a user loads a page and the ad pops up, it counts as one impression.
These platforms aim to generate maximum total revenue from transactions, that’s why they must use algorithms that will allocate buyer impressions (show buyer requests on items) to the most appropriate potential merchants.
Most platforms use such recommendation methods as collaborative filtering or content-based filtering. These algorithms rank merchants using their “historical scores” that rely on the transaction history of the sellers with customers of similar characteristics. Sellers experiment with prices to get higher ranking positions, and these algorithms don’t take into account changes in pricing schemes.
As a solution to this problem, researchers applied a general framework of reinforcement mechanism design. The framework uses deep reinforcement learning to develop efficient algorithms that evaluate sellers’ behavior.
Online merchants can also conduct fraudulent transactions to improve their rating on eCommerce platforms to draw more buyers. And that, according to researchers, decreases the efficiency of use of buyer impressions and threatens the business environment. However, it’s possible to improve the platform's impression allocation mechanism while increasing its profit and minimizing fraudulent activities with reinforcement learning.
In the article on AI and DS advances and trends, we discussed another RL use case – real-time bidding strategy optimization. It allows businesses to dynamically allocate the advertisement campaign budget “across all the available impressions on the basis of both the immediate and future rewards.” During real-time bidding, an advertiser bids on an impression, and their ad is displayed on a publisher’s platform if they win an auction.
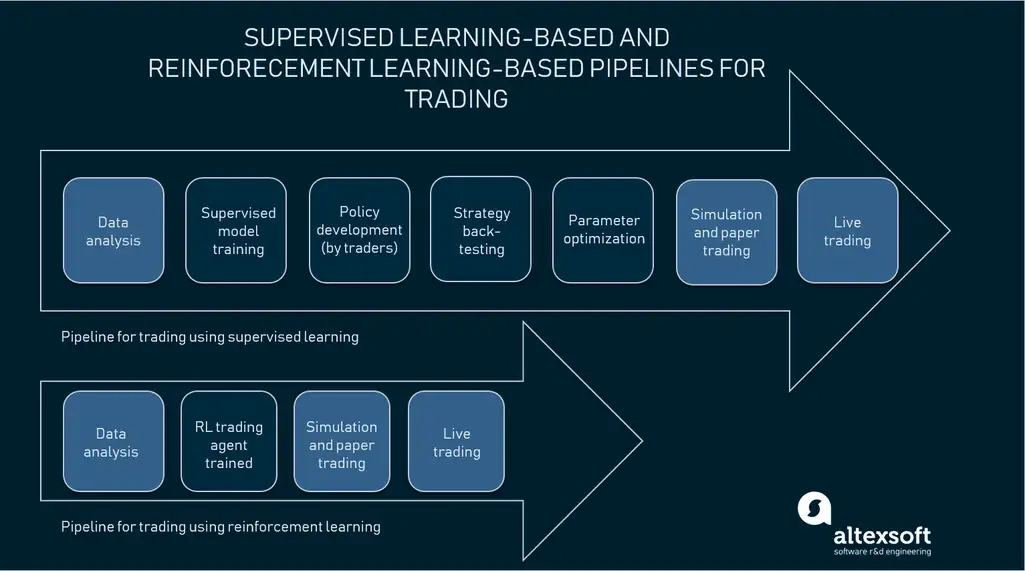
Trading in financial industry
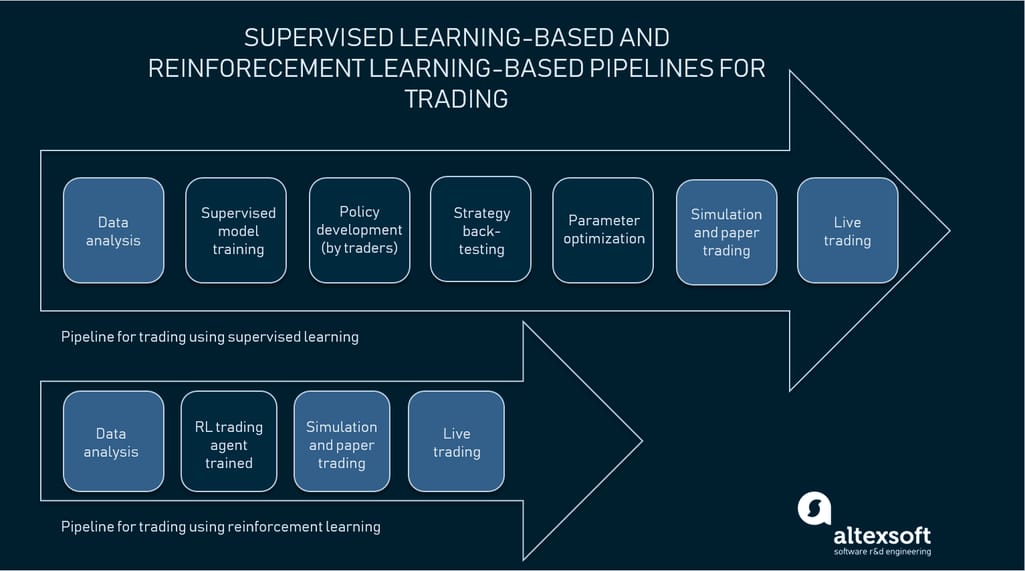
Financial institutions use AI-driven systems to automate trading tasks. Generally, these systems use supervised learning to forecast stock prices. What they can’t do is to decide what action to take in a specific situation: to buy, sell, or hold. Traders still must make business rules that are trend-following, pattern-based, or counter-trend to govern system choices. Because analysts may define patterns and confirmation conditions in different ways, there is a need for consistency.
Michael Kearns, computer science professor at the University of Pennsylvania, hired by Morgan Stanley, stock trading firm, in June 2018 noted that RL models allow for making predictions that take into account outcomes of one's actions on the market. In addition, traders may also learn about the most appropriate time for action and/or the optimum size of a trade.
IBM built a financial trading system on its Data Science Experience platform that utilizes reinforcement learning. “The model winds around training on the historical stock price data using stochastic actions at each time step, and we calculate the reward function based on the profit or loss for each trade,” said Aishwarya Srinivasan from IBM. Developers use active return on investment to evaluate the model’s performance. An active return is the difference between the benchmark and the actual return expressed as a percentage.
Specialists also evaluate the performance of the investment against the market index that represents market movement in general. “Finally, we assess the model against a simple Buy-&-Hold strategy and against ARIMA-GARCH. We found that the model had much-refined moderation according to the market movements, and could even capture the head-and-shoulder patterns, which are non-trivial trends that can signal reversals in the market,” added Srinivasan.
Autonomous vehicles training
Reinforcement learning has proven to be an effective method for training deep learning networks that power self-driving car systems. UK company Wayve claims to be the first one to develop a driverless car that works with the help of RL.
Wayve specialists train a self-driving car with reinforcement learning
Developers generally write a large list of hand-written rules to tell autonomous vehicles how to drive. And, that has led to slow development cycles. Wayve specialists chose the other way. They spent only 15-20 minutes to teach a car from scratch to follow a lane through trial and error. A human driver that was in the vehicle during an experiment intervened when the algorithm made a mistake and the car was going off track. The algorithm was rewarded for a distance driven without intervention. That way a car has learned online getting better in driving safely with every exploration episode. Researchers explain the technical side of training in their blog post.
Robotics
Numerous problems in robotics can be formulated as reinforcement learning ones. A robot learns optimal sequential actions to complete a task with a maximum cumulative reward through exploration by receiving feedback from the environment. Developers don’t give it detailed instructions for solving a problem.
The RL in robotics survey authors point out that reinforcement learning provides a framework and a range of tools for the design of sophisticated and hard-to-engineer behaviors.
Specialists from the Google Brain Team and X company introduced a scalable reinforcement learning approach to solving a problem of training vision-based dynamic manipulation skills in robots. The goal was to train robots to grasp various objects, including objects unseen during training.
They combined deep learning and RL technique to enable robots to continuously learn from their experience and improve their basic sensorimotor skills. Specialists didn’t have to engineer behaviors themselves: Robots automatically learned how to complete this task. Specialists designed a deep Q-learning algorithm (QT-Opt) that employs data collected during past training episodes (grasping attempts).
Seven robots have been trained with more than 1000 visually and physically diverse objects for 800 hours over four months. A camera image was analyzed to suggest how a robot should move its arm and gripper.
Robots are collecting grasp data. Source: Google AI Blog
The novel approach led to a 96 percent success rate of the grasp attempts across 700 test grasps on previously unseen objects. A supervised-learning based approach the specialists used before showed a 78 percent-success rate.
It also turned out that the algorithm achieves that accuracy while requiring less training data (although the training time was longer).
Industrial automation
RL has a potential to be widely used in industrial settings for machinery and equipment tuning supplementing human operators. Bonsai is one of the startups that provides a deep reinforcement learning platform for building autonomous industrial solutions to control and optimize the work of systems.
For instance, customers can improve energy efficiency, reduce downtime, increase equipment longevity, and control vehicles and robots in real time. You can listen to the O’Reilly Data Show podcast in which Bonsai CEO and founder describes various possible RL use cases for companies and enterprises.
Google uses the power of reinforcement learning to become more environmentally friendly. The tech company’s IA research group, DeepMind, developed and deployed RL models that helped reduce energy consumption for cooling data centers by up to 40 percent and decreased total energy overhead by 15 percent.
Challenges to implementing reinforcement learning in business
The application of RL for solving business problems may pose serious challenges. That’s because this technique is exploratory in nature. The agent collects data on the go since there is no labeled or unlabeled data to guide it with a task goal. The decisions taken influence the data received. That’s why the agent may need to try out different actions to get new data.
Environment unpredictability. An RL algorithm may perform exceptionally when trained in closed, synthetic environments. In video games, for example, conditions under which the agent repeats its decision process don’t change. That’s not the case for the real world. It’s for these reasons that industries like finance, insurance, or healthcare think twice before investing their money into trials of RL-based systems.
Delayed feedback. In real-life applications, it’s uncertain how much time would be required to realize the outcome of a specific decision. For example, if an AI trading system predicts that the investment in some assets (real estate) would be beneficial, we’ll need to wait a month, year, or several years until we figure out whether that was a good idea.
Infinite time horizons. In RL, an agent's number one goal is to get the highest reward possible. As we don't know how much time or tries it will take, we have to establish an infinite horizon objective. For instance, if we were testing a self-driving car (that uses RL) to switch lanes, we couldn’t tell how many times it will hit other vehicles on the road until it does it right.
Defining a precise reward function. Data scientists may struggle with expressing the definition of good or bad action mathematically, computing a reward for the action. The advice is to think about reward functions in terms of current states, allowing the agent to know whether the action it is about to take will help it get closer to a final goal. For example, if there is the need to train a self-driving car to turn right without hitting a fence, sizes of reward functions would depend on the distance between a car and a fence and the start of steering.
Data problem and exploration risks. RL requires even more data than supervised learning. “It is really difficult to get enough data for reinforcement learning algorithms. There’s more work to be done to translate this to businesses and practice,”said computer scientist and entrepreneur Andrew Ng during his speech at the Artificial Intelligence Conference in San Francisco 2017. Just imagine what chaos the self-driving vehicle’s system could cause if it was tested solely on a street: It can hit neighbor cars, pedestrians, or smash into a guardrail. So, testing devices or systems using RL in a real environment can be difficult, financially irrational, and dangerous. One of the solutions is to test it on synthetic data (3D environments) while taking into account all the possible variables that may influence the agent’s decision at each situation or time step (pedestrians, road type and quality, weather conditions, etc.)
Conclusion
Despite training difficulties, reinforcement learning finds its way to be effectively used in real business scenarios. Generally, RL is valuable when searching for optimal solutions in a constantly changing environment is needed.
Reinforcement learning is used for operations automation, machinery and equipment control and maintenance, energy consumption optimization. The finance industry also acknowledged the capabilities of reinforcement learning for powering AI-based training systems. Although trial-and-error training of robots is time-consuming, it allows robots to better evaluate real-world situations, use their skills for completing tasks, or reacting to unexpected consequences appropriately. In addition, RL provides opportunities for eCommerce players in terms of revenue optimization, fraud prevention, and customer experience enhancement via personalization.