

When reviewing BI tools, we described several data warehouse tools. In this article, we'll take a closer look at the top cloud warehouse software, including Snowflake, BigQuery, and Redshift. We’ll review all the important aspects of their architecture, deployment, and performance to help you make an informed decision.
Before jumping into a comparison of available products, it's a good idea to first get acquainted with data warehousing basics.
What is a data warehouse?
A data warehouse is defined as a centralized repository where a company stores all valuable data assets integrated from different channels like databases, flat files, applications, CRM systems, etc. A data warehouse is often abbreviated as DW or DWH. You may also find it referred to as an enterprise data warehouse (EDW). It is usually created and used primarily for data reporting and analysis purposes. Thanks to the capability of data warehouses to get all data in one place, they serve as a valuable business intelligence (BI) tool, helping companies gain business insights and map out future strategies.To learn more about data engineering check our article or watch a video


Data engineering, explained
According to Bill Inmon, the data warehousing pioneer, there are several defining features of a DW:
Subject-oriented signifies that the data information in the warehouse revolves around some subject as compared to a data lake. It means that a warehouse doesn’t contain all company data ever but only subject matters of interest. As an illustration, a particular warehouse can be built to track information about sales only.
Read our dedicated article on data lake vs data warehouse to learn about their differences.
Integrated means that the data warehouse has common standards for the quality of data stored. For instance, any organization may have a few business systems that track the same information. A data warehouse acts as a single source of truth, providing the most recent or appropriate information.
Time-variant relates to data warehouse consistency during a particular period when data is carried into a repository and stays unchanged. For example, companies can work with historical data to know what sales were like 5 or 10 years ago in contrast to current sales.
Non-volatile implies that once the data flies into a warehouse, it stays there and isn't removed with new data entries. As such, it is possible to retrieve old archived data if needed.
Summarized touches upon the fact the data is used for data analytics. Often, it is aggregated or segmented in data marts, facilitating analysis and reporting as users can get information by unit, section, department, etc.
Data warehouse architecture
The architecture of a data warehouse is a system defining how data is presented and processed within a repository. Warehouses can be divided into those following a traditional approach to storing and processing data versus modern cloud-based ones. Cloud systems are designed to fill in the gaps of legacy databases and address modern data management challenges. Let's go through the architectural components of both.
Traditional data warehouse architecture
Traditional or on-premise data warehouses have three standard approaches to constructing their architecture layers: single-tier, two-tier, and three-tier architectures. The most common one is the three-tier model, composed of the bottom, middle, and top tiers.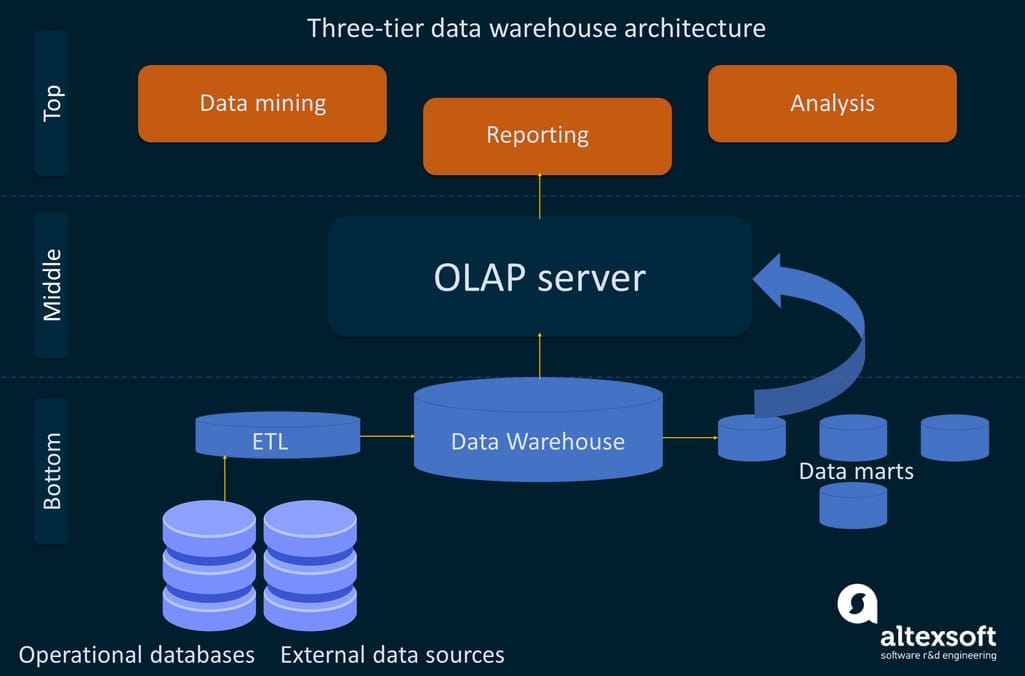
Three-tier data warehouse architecture.
The bottom tier is represented by systems of report, usually relational database systems. A variety of back-end tools make it possible to extract, clean, transform, and load data into this layer. There are two different approaches to loading data into a data warehouse: ETL and ELT. Both processes include the Extract, Load, Transform functions but with a different sequence.
The middle tier serves as a mediator between the database and the end-user. It is a home for an OLAP (online analytical processing) server that converts data into a form more suitable for analysis and querying.
The top tier is referred to as the front-end or client layer. It contains an API (Application Programming Interface) and tools designed for data analysis, reporting, and data mining (the process of detecting patterns in large datasets to predict outcomes).
Cloud data warehouse architecture
Being relatively new, cloud warehouses more commonly consist of three layers such as compute, storage, and client (service). The compute layers comprise multiple compute clusters with nodes processing queries in parallel. Compute clusters are the sets of virtual machines grouped to perform computation tasks. These clusters are sometimes called virtual warehouses. In the storage layers, data is organized in partitions to be further optimized and compressed. The client layers are responsible for management activities. Although cloud-based data warehouse vendors often use slightly different approaches to constructing their architectures.
Cloud data warehouses can be categorized in multiple ways.
By the type of deployment:
- Cloud-based data warehouses that use the computation power and space presented by cloud providers.
- Hybrid cloud data warehouses adopt cloud capabilities while still allowing the use of on-premises solutions.
By generation:
- The 1st generation data warehouses are built using the SMP architecture or Symmetric Multiprocessing where multiple processors are attached to a single node.
- The 2nd generation Data Warehouses separate the compute and storage layers, relying on the MPP (Multiple Parallel Processing) architecture with multiple nodes processing different queries at the same time.
- The 3rd generation data warehouses add more computing choices to MPP and offer different pricing models.
By the level of back-end management involved:
- Serverless data warehouses get their functional building blocks with the help of serverless services, meaning they are fully-managed by third-party vendors. The term "serverless" doesn't imply that there are no servers at all, but rather that a person or a company using the system doesn't buy or rent any physical or virtual servers.
- DWs with servers, meaning a person or a company can rent, set up, and manage virtual servers for warehousing.
While traditional data warehouses are still alive and kicking, especially for storing sensitive data or working with close integrations of related structured data types, they lag behind modern cloud solutions big time. The variety of data explodes and on-premises options fail to handle it. Apart from the lack of scalability and flexibility offered by modern databases, the traditional ones are costly to implement and maintain.
Modern cloud solutions, on the other hand, cover the needs of high performance, scalability, and advanced data management and analytics. At the moment, cloud-based data warehouse architectures provide the most effective employment of data warehousing resources.
How to choose cloud data warehouse software: main criteria
Data storage tends to move to the cloud and we couldn't bypass reviewing some of the most advanced data warehouses in the big data arena. To provide the most relevant information and unbiased opinions, all the data warehouse solutions are going to be compared based on the same criteria.
Criteria to consider when choosing cloud data warehouse products.
Architecture. Cloud-based data warehouses differ, and so do their approaches to organizing architectural components. And yet, pretty much all of them rely on massively parallel processing or MPP. There are shared-nothing or shared disk MPP architectures.
- In a shared-nothing architecture, nodes (processors) work independently and don't share disk space. Different data is processed in parallel on different nodes.
- In a shared-disk, the processing is also performed on different nodes, but, as the name suggests, they are connected by a single memory disk, meaning all cluster nodes have access to all data.
Shared-nothing solutions are great if you are a large-scale company, with millions of users to serve daily. They also require a more intricate partitioning strategy and, ideally, avoiding operations that span across multiple storages. In many cases, a shared-disk architecture may be enough. However, in today’s world, there are warehouse designs that can use both approaches simultaneously, like Snowflake.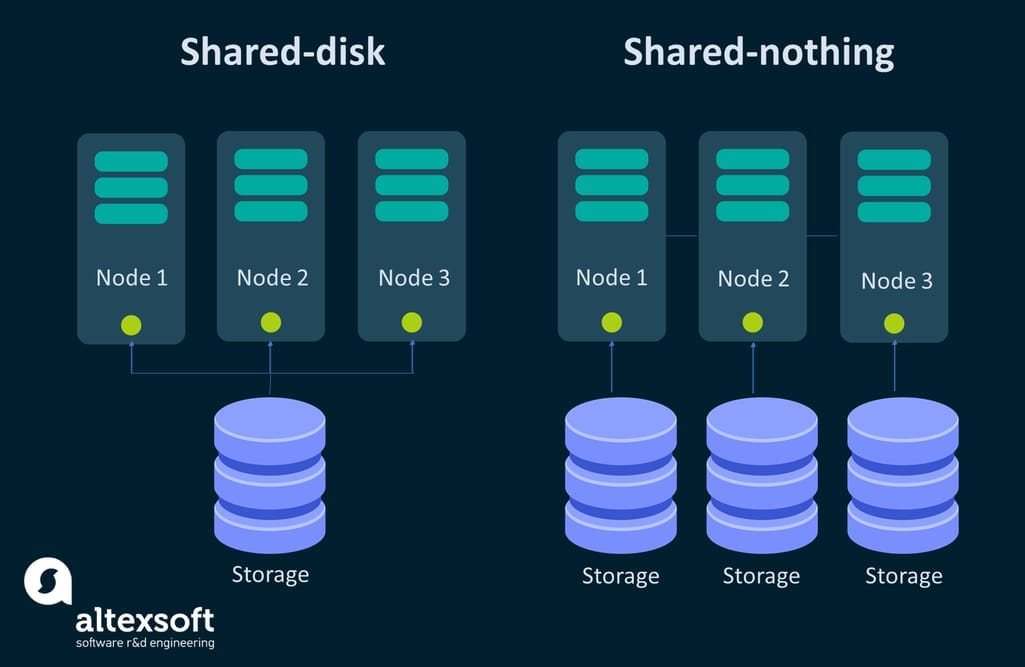
Shared-disk and shared-nothing architectures displayed.
Performance and data processing speed. Better performance reduces expenses as quite a few providers charge for the time you use their compute powers. So, you may want to find out how much time it takes for each solution to run queries. Another important factor resides in whether a product supports concurrent querying that speeds up performance.
Scalability opportunities. Scaling allows companies to take control of their system performance and storage bandwidth, which optimizes the usage of resources and saves money. Depending on the type of scaling used by vendors (horizontal or vertical), you will either add more machines to your pool of resources or add more power such as CPU or RAM to your existing system to meet your needs.
Offered security measures. From keeping a data warehouse compliant with the required data protection regulations to providing advanced user access management, a vendor you choose must employ all the needed measures to protect sensitive data.
Third-party integration support. Data warehouses often integrate with other systems. It is a good idea to check if it is possible to integrate a particular DW with your existing software tools as it can speed up the process of data migration into the cloud.
Data loading. It’s a good thing to learn what types of data injection and what access methods the solution provides. Will it be possible to ingest data in real-time or in batches? Since we are comparing top providers on the market, they all have powerful data loading capabilities, including streaming data.
Support for data backup and recovery. To minimize worries about your data, it is better to ask your vendor what disaster recovery and data backup measures they provide upfront.
Deployment scenarios. Based on business needs and budget, companies have to decide which deployment option suits them best: on-premise, cloud, or hybrid. What's more, the ease of data warehouse deployment and its further use also should be taken into account.
Implementation process. Each company has its own needs and available resources. Consequently, the service implementation process is one of the determining factors for a business. What configuration opportunities does each solution offer? Is it easy or difficult to implement? Is it time-consuming? What specialists are required to handle a data warehouse and what would their expertise level have to be? Remember that all of the warehouse products available require some technical expertise to run, including data engineering and, in some cases, DevOps.
Price. Find out if a vendor offers a free trial to test the waters before a purchase. Is it a flat-rate or on-demand model? Also, be attentive as some packages don't include all the functionality.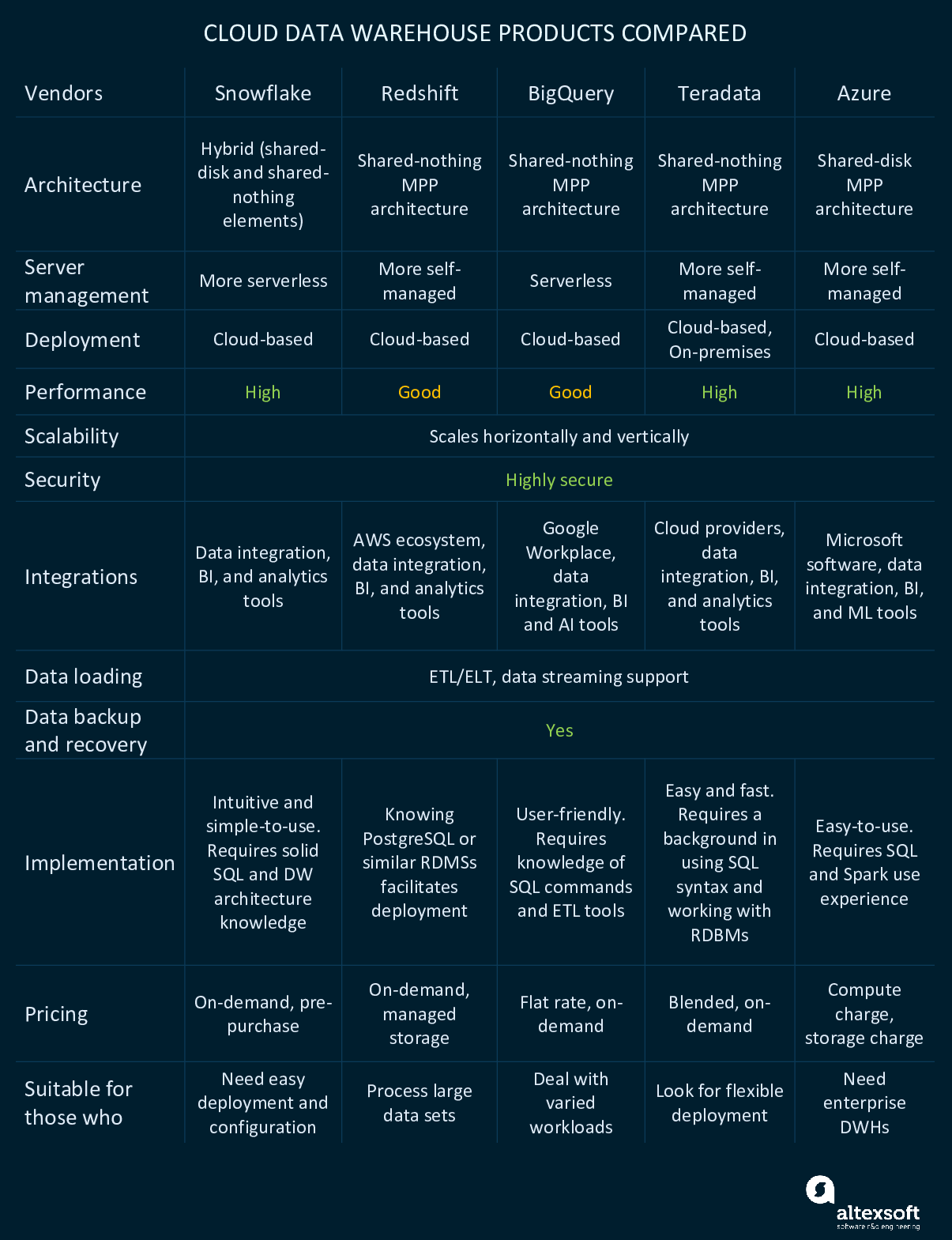
Comparison of the top data warehouse software products.
Snowflake: for corporations in search of the easy deployment and configuration
Initially built on top of AWS (Amazon Web Services), Snowflake is an all-inclusive cloud data warehouse for structured and semi-structured data provided as Software-as-a-Service (SaaS). As a customer, you don’t need to select, install, or manage any virtual or physical hardware, except for configuring the size and number of compute clusters. The rest of the maintenance duties are carried by Snowflake, which makes this solution practically serverless. Unlike traditional warehousing offerings, Snowflake provides more flexible, faster, and easier-to-use data storage and analytic solutions.
Architecture. Snowflake's architecture is natively designed for the cloud and combined with an innovative SQL query engine. Combining the characteristics of traditional shared-disk and shared-nothing database architectures, Snowflake comprises three core layers such as database storage, query processing, and cloud services. There is a centralized data repository for a single copy of data that can be accessed from all independent compute nodes.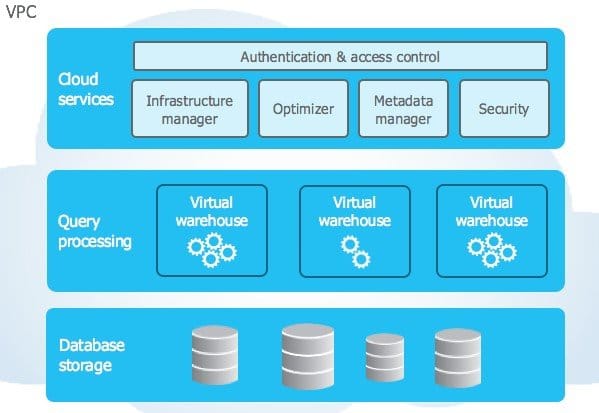
Snowflake architecture illustration. Source: Snowflake
Performance. Thanks to the concept of separate compute and storage, Snowflake allows for concurrent workloads, meaning users can run multiple queries at a time. The workloads won't impact each other, which results in faster performance (according to one of the benchmarks, Snowflake is capable of processing 6 to 60 million rows of data in from 2 seconds to 10 seconds).
Scalability. Snowflake enables seamless, non-disruptive scaling (both horizontal and vertical) powered by multi-cluster shared data architecture. It doesn’t require the involvement of a database operator or admin to scale as the software handles all the scaling automatically per business demand. That’s a huge advantage for smaller companies with limited resources.
Security. Snowflake is highly secure and fully compliant with most data protection standards, including SOC 1 Type 2, SOC 2 Type 2 for all Snowflake editions and PCI DSS, HIPAA, HITRUST for the Business Critical Edition or higher. The system also provides controlled access management and high-level data security (all data and files are automatically encrypted).
Integrations. The system provides native connectivity with multiple data integration, BI, and analytics tools, including IBM Cognos, Azure Data Factory, Oracle Analytics Cloud, Fivetran, and Google Cloud, to name a few.
Data loading. Snowflake supports the ELT and ETL data integration approaches, meaning data transformation can happen during or after loading. The ELT approach helps with capturing raw data and then finding the best use case for it. It’s important if you plan on designing machine learning models. The files can be loaded from cloud storage like Microsoft Azure or Amazon S3. Snowflake is also a good choice for data streaming. But keep in mind that all providers we compare here support data streaming. So, it’s not going to be a differentiating feature in this article.
Data backup and recovery. The platform uses fail-safe instead of backup. Fail-safe offers a 7-day period during which Snowflake recovers data that may have been damaged or lost due to system failures.
Implementation. Snowflake is considered one of the most intuitive and simplest to use data warehouse products and it evokes a serverless experience. Having inherited a lot of relational database features and combined them with cloud principles, the service promises a quick and easy start. The platform allows for creating and maintaining multiple data warehouses using one account. The sizes of the compute cluster per warehouse can be configured in detail. All of this sounds great, but configuring Snowflake still requires solid SQL knowledge and skills as well as a good understanding of data warehouse architecture. To help you out, Snowflake provides explicit documentation as well as opportunities to become a certified Snowflake expert.
Price. Snowflake provides tiered pricing that is tailored to customer requirements and needs. There are on-demand and pre-purchase pricing plans. As the usages of storage and compute are separated, the latter is billed separately on a per-second basis (minimum 60 seconds).
Suitable for: Companies looking for an easily deployed DWH with nearly unlimited, automatic scaling and top-notch performance will benefit from using Snowflake.
Amazon Redshift: enterprise data warehouse tool
Part of Amazon's cloud-computing platform, Redshift is a cloud-based data warehouse software for enterprises. The platform enables fast processing of massive data sets. Not only is it fit for quality data analytics, it also provides automatic concurrency querying as per workload demand. Regardless of some managed features that we describe in the implementation section, Redshift is a more self-managed solution meaning that engineers will have to spend time on resource and server management.
Architecture. Redshift is designed with the shared-nothing MPP architecture. It comprises data warehouse clusters with compute nodes split up into node slices. Individual compute nodes are assigned with the code by the leader node. The system communicates with client applications by using industry-standard JDBC and ODBC drivers. The technology can be integrated with most existing SQL-based client applications, ETL, BI, data analytics, and data mining tools.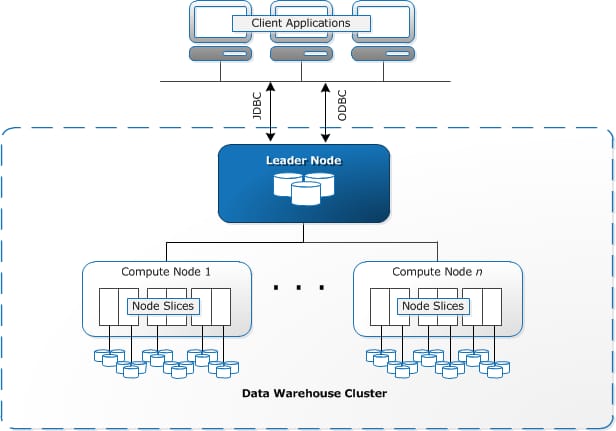
Illustration of Amazon Redshift warehouse architecture. Source: AWS
Performance. While the performance is fine overall on most data types, it is quite low when using semi-structured data (e.g. JSON files). For optimal performance, it is recommended that users opt for the concept of distribution keys. These are columns used to define a database segment storing a particular row of data.
Scalability. Redshift allows for horizontal and vertical scaling. It is pre-configured to support 500 concurrent connections and up to 50 concurrent queries to be run at the same time in a cluster. That means up to 500 users can execute up to 50 queries at any given time in one cluster. In case you need to process more concurrent read queries, Redshift provides the concurrency scaling feature that automatically adds the capacity of another cluster. Different clusters can be used for different use cases while accessing the same data.
Security. With Redshift, you share security responsibilities with AWS: Security of the cloud is taken care of by AWS while security in the cloud is your responsibility. As security is of the highest priority to AWS, access to Redshift resources is controlled thoroughly at all levels. Redshift provides compliance with security standards, including ISO, PCI, HIPAA BAA, and SOC 1,2,3.
Integrations. The software tool provides robust integration opportunities with the whole AWS ecosystem, including Amazon S3, Amazon RDS, Amazon DynamoDB, Amazon EMR, AWS Glue, and AWS Data Pipeline. Redshift partners with a huge number of other platforms.
Data loading. While supporting both ELT/ETL approaches and standard DML (data manipulation language) commands including INSERT, Redshift claims that the most effective way to load data into your tables is to use their COPY command. With this command, it is possible to simultaneously work with multiple data streams and read data from multiple data files. The platform also offers real-time data streaming capabilities.
Data backup and recovery. Amazon Redshift uses the advanced system of both automated and manual snapshots ‒ point-in-time backups of a cluster. They are stored in Amazon S3 by means of an encrypted SSL connection.
Implementation. Redshift's query engine resembles the PostgreSQL interface. Therefore, if your company has a team of data analysts who previously dealt with PostgreSQL or similar SQL-based management systems, it will be easy for you to start creating and processing queries in Redshift for your BI. Also, Redshift automates some of the most time-consuming cluster configuration responsibilities such as data backups, patching, replications, and facilitating the administration of a warehouse. One way or another, there should be a certain level of data engineering and server management expertise to work with Redshift: A DevOps or data engineer must configure clusters and define memory, compute, and storage allocation. For these reasons, Redshift falls more to the self-managed side of the spectrum.
Price. Redshift offers various pricing plans. With on-demand pricing, charges are set per hour. While it starts at only $0.25 an hour, the final cost is calculated based on the number of nodes in a cluster. With managed storage pricing, users pay for the volume of data per month.
Suitable for: Redshift is initially made for big data warehousing. If your company deals with large scale data and your queries need quick responses, you should definitely give serious consideration to Redshift. The platform is also a good fit for businesses that are looking for a data warehouse with a transparent pricing model and little to no administrative overhead costs.
Google BigQuery fits corporations with varied workloads
Developed by Google, BigQuery does exactly what the name suggests ‒ provides opportunities for querying large data sets. This is a cost-effective multi-cloud data warehouse technology possessing machine learning capabilities.
Architecture. BigQuery possesses a serverless architecture where storage and compute are separated. The main component of BigQuery architecture is called Dremel. This is a massively parallel query engine with the functionality to read thousands of rows in seconds. Data is stored in replicated, distributed storage, and processed in compute clusters consisting of nodes. This structure provides vast flexibility and differs from traditional on-premise or node-based cloud data warehouse technologies. With such an approach under the hood, various users can put their data into the data warehouse and start analyzing that data using Standard SQL.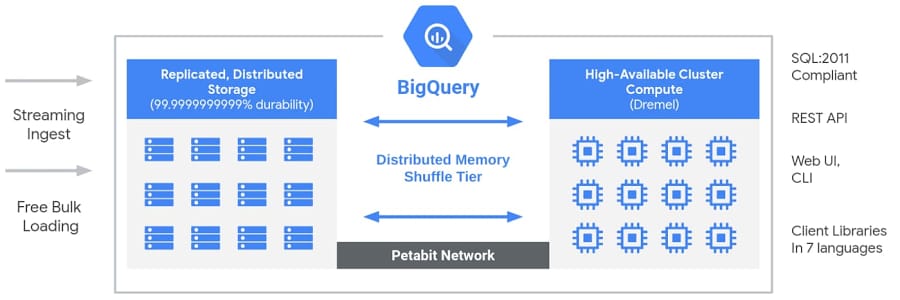
Representation of BigQuery architecture. Source: Google BigQuery.
Performance. BigQuery supports partitioning, resulting in improved query performance. The data can be easily queried with either SQL or through Open Database Connectivity (ODBC). According to the Fivetran benchmark, Google BigQuery shows good but not top-tier performance ‒ the average runtime of 99 TPC-DS queries (each TPC-DS consists of 24 tables with the largest one containing 4 million rows of data) is 11.18 seconds. Redshift and Snowflake showed 8.24 and 8.21 seconds respectively.
Scalability. Similar to Snowflake, BigQuery sets apart compute and storage, enabling users to scale processing and memory resources based on their needs. The tool obtains high vertical and horizontal scalability and executes real-time queries on petabytes of data relatively fast.
Security. To secure sensitive data, BigQuery offers column-level security allowing for creating policies and checking access status, Cloud DPL (cloud data loss prevention), and encryption keys management. As a part of the Google Cloud environment, BigQuery provides a huge number of compliance offerings such as HIPAA, FedRAMP, PCI DSS, ISO/IEC, SOC 1,2,3, to name a few.
Integrations. Apart from operational databases, the system allows for integration with a wide array of data integration tools, BI, and AI solutions. It also integrates with Google Cloud Platform systems, which makes it a great choice as quite a few companies these days use Google Workspace, previously known as G Suite.
Data loading. Along with traditional ETL/ELT batch data loading by the means of a standard SQL dialect, BigQuery allows for data streaming ‒ ingesting data row-by-row in real-time using the streaming API (insertAll).
Data backup and recovery. BigQuery services include data backup and disaster recovery. Users are allowed to query point-in-time snapshots from 7 days of data changes.
Implementation. As far as the usability scale, BigQuery ranks high owing to the fully-managed nature of its data warehouses, meaning the BigQuery engineering team handles maintenance and updates and takes a lot of weight off your shoulders. But that doesn't mean that you don't need a data science team at all. The platform requires the knowledge of SQL commands and ETL tools. With the right experts, the processes of setup and configuration aren't time-consuming and you can start working with BigQuery quite quickly.
Price. As for BigQuery pricing, the platform offers on-demand and flat-rate subscriptions. Although you will be charged for data storage ($0.020 per GB per month) and querying ($5 per TB), things like exporting, loading, and copying data are free.
Suitable for: BigQuery will be the best fit for corporations with varied workloads and those interested in effective data mining. If you don't work with very big data volumes and query response time of up to several minutes isn't critical when you use that data to run queries, then BigQuery can be a great candidate.
Teradata: perfect for businesses needing deployment flexibility
Teradata has gained remarkable recognition as a powerful enterprise data warehouse that has provided scalable storage facilities and robust data analytics for over 35 years. It is one of the most efficient hybrid cloud data warehousing tools for processing huge volumes of data. Teradata offers deployment flexibility meaning a DW can be deployed on-premises, in a private cloud, in a public cloud, or within a hybrid cloud setting. While Teradata is more of a self-managed solution, their private cloud, called Teradata IntelliCloud, offers fully-managed services.
Architecture. Just like some other data warehouse products in the list, the Teradata engine is built on the shared-nothing MPP architecture, meaning that users can run multiple concurrent queries at a time. The architecture has four components: the parsing engine (the communicator between the client system and the AMPs), BYNET (the networking layer), AMPs (access module processors), and Disks (storage space).
Teradata architecture illustration. Source: javaTpoint
Performance. With Teradata, businesses can count on high performance. The optimized performance is also reached thanks to the employment of in-memory processing (the processing of data using RAM or flash memory). The system divides data into hot and cold where hot refers to more frequently used data.
Scalability. The system has the capability of scaling from 100 gigabytes to over 100+ petabytes of data without compromising established performance. With Teradata, the system does both vertical and horizontal scaling, meaning users can add to or remove nodes from the system as well as add or remove CPU and memory per their needs.
Security. Teradata obtains various information security features from user-level security controls to network traffic encryption. The platform is fully compliant with strict security regulations from HIPAA, GDPR, PCI to ISO 27001, FISC, and SOC 1 and 2.
Integrations. A Teradata data warehouse can be integrated with Informatica, Google Cloud, Microsoft Azure, and other leading cloud providers.
Data loading. Teradata has a self-service solution for ingesting and administering data streams in real-time called Listener. It also supports both ELT and ETL approaches.
Data backup and recovery. Teradata provides complete data protection with its robust Backup and Restore solution that ensures an automated backup process and rapid recovery in case of operational failures.
Implementation. With Teradata, it's pretty easy and quick to get a data warehouse up and running. Most users concur that the system is overall user-oriented and convenient. While it requires a background in the use of SQL syntax, working with database management systems, and reading architectural descriptions, finding data specialists with fitting expertise is a no-brainer both onshore and offshore. The self-managed nature of Teradata on-prem solutions should be taken into account because configuration tasks rest on the shoulders of your DevOps and data engineers. The system provides documentation for all the configuration steps.
Price. The platform offers blended (a combination of flat and on-demand pricing) and consumption (on-demand) pricing models to help businesses use their budget efficiently.
Suitable for: Teradata is the only option from the list that offers deployment flexibility. So, it will be beneficial for businesses that need both on-premises and cloud solutions, or either of the two. Those who are looking for advanced business analytics and decision making will also reap benefits by using Teradata. The system can be used to analyze huge amounts of data and provide real-time analytics.
Azure Synapse by Microsoft (formerly SQL Data Warehouse)
Created by the technology giant Microsoft, Azure Synapse data warehouse serves as a cloud relational database with the opportunity of loading and processing petabytes of data as well as real-time reporting. Owing to seamless integration with the Microsoft SQL Server, the solution is a perfect match for organizations that seek easy transitioning to cloud-based warehouse technology.
Architecture. The system is built on nodes and a shared-disk massively parallel processing architecture, providing users with the capabilities of running more than a hundred parallel queries simultaneously. The Control node gets T-SQL commands from applications connected to it, prepares queries for concurrent processing, and sends operations to Compute nodes.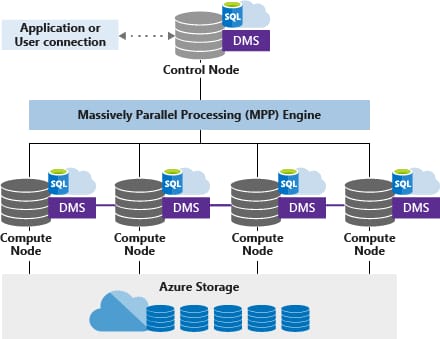
Depiction of Azure's MPP architecture. Source: Microsoft
Performance. The architecture allows for concurrent query processing. As such, users can extract and visualize business insights quite fast. If we take the GigaOm benchmark, we'll see that Azure shows the best performance as it took the least aggregate time (2,996 seconds) to execute 103 queries.
Scalability. Azure is known for being an extremely scalable and elastic cloud service, which can be scaled up and down (horizontally and vertically) fast per requirements.
Security. Azure provides a variety of comprehensive data protection services for workloads in the cloud and on-premises. They include information security, access management, network security, threat protection, and data protection. The Microsoft service presents more than 90 compliance certifications such as HITRUST, HIPAA, ISO, NIST CSF, and many more.
Integrations. Azure has a set of integration tools such as API Management, Logic Apps, Service Bus, and Event Grid to connect with a wide array of third-party services. The system natively integrates with operational databases, BI, and ML software.
Data loading. Azure allows for ingesting huge volumes of data from over 95 connectors by creating ETL/ELT processes in a code-free environment.
Data backup and recovery. Microsoft offers a built-in solution used to back up and restore data resources called Azure Backup. It scales based on your backup storage needs.
Implementation. Azure excels at ease-of-use. Users who know Microsoft products will experience little to no headaches when implementing a data warehouse. But keep in mind that those who aren't used to the Microsoft environment might find Azure a bit difficult to learn. For analytic workloads, a company will need specialists who have hands-on experience using SQL and Spark. While Azure Synapse allows for leveraging serverless capabilities for database resources on-demand, the solution is referred to as more self-managed. Consequently, you will need experienced data engineers to configure the warehouse. The integrated development environment called Synapse Analytics Studio is nearly code-free. Azure provides clear instructions, well-organized documentation, and useful tutorials. Not to mention an intuitive interface.
Price. As far as the pricing of Azure SQL data warehouse, it is divided into a compute charge and a storage charge. When paused, you will not be charged for compute, only for storage. There are no upfront costs and termination fees.
Suitable for: Azure Synapse is a perfect match for enterprise DWHs as it offers a great price/performance ratio. It is also a win-win solution for companies that already use Microsoft products and need seamless integrations.
Reasons to choose modern cloud data warehouse products
The business environment has become highly competitive. To stay up to the minute, organizations increasingly turn from traditional on-premises platforms to more advanced cloud-based data warehouses. Here’s why:
- There's no need to buy expensive physical hardware and hire an in-house team of specialists to maintain it.
- Cloud warehouses are much easier to set up and run.
- The absence of capital expenditure and low operational expenses are attractive features.
- Great scalability opportunities come at more affordable prices.
- The ability of modern warehouse architectures to perform complex analytical queries at a much faster pace due to their use of massively parallel processing (MPP) is an excellent option.
All of the above data warehouse vendors are worthy candidates if you need to migrate your data into the cloud. The checklist we provided here and the comparison of available products should help you assess whether or not a certain end-to-end solution fills the bill. And yet, some companies may find it difficult to decide which solution suits their workflows best or to figure out how to implement cloud DWHs by themselves. If this is the case, it is better to opt for the professional help of third-party providers with hands-on experience in data warehousing implementation and consulting.